
识别实体的主观属性
已发表: 2022-05-13识别实体的 UGC 主观属性
这项最近授予的专利是关于识别实体的主观属性。
我还没有看到关于实体的主观属性或对这些实体的响应的专利。
它的一个关键方面是它是用户生成的内容。
我们被告知,由于社交网络、博客、评论网站等的日益普及,用户生成的内容 (UGC) 在网络上变得越来越普遍。
我们经常看到用户生成的内容以评论的形式出现,例如:
- 第一个用户对社交网络中第二个用户共享的内容的评论
- 用户评论以回应专栏作家博客中的文章
- 来自内容托管网站上发布的视频剪辑的评论
- 评论(例如产品、电影)
- 操作(例如喜欢!、不喜欢!、+1、分享、书签、播放列表等)
- 以此类推
根据该专利,提供了一种识别和预测实体(例如媒体剪辑、图像、报纸文章、博客条目、个人、组织、商业企业等)的主观属性的方法。
它开始于:
- 基于对第一实体的反应(例如网站上的评论、对第一实体的批准证明(例如“喜欢!等)”识别第一实体的第一组主观属性
- 共享第一个实体
- 为第一个实体添加书签
- 将第一个实体添加到播放列表
- 在一组输入-输出映射上训练分类器(例如支持向量机、AdaBoost、神经网络、决策树,其中输入-输出映射集包括输入-输出映射,其输入为提供特征向量对于第一个实体,其输出基于第一组主观属性
- 将第二个实体的特征向量提供给经过训练的分类器,以获得第二个实体的第二组主观属性
提供存储器和处理器来识别和预测实体的主观属性。
计算机可读存储介质具有使计算机系统执行操作的指令,包括:
- 基于对第一实体的反应识别第一实体的第一组主观属性
- 获得第一实体的第一特征向量
- 在一组输入-输出映射上训练分类器,其中该组输入-输出映射包括输入-输出映射,其输入基于第一特征向量,其输出基于第一主观属性集
- 获得第二个实体的第二个特征向量
- 提供给分类器,经过训练,第二个特征向量得到第二个实体的第二组主观属性
这项关于识别实体主观属性的专利=可在以下位置找到:
通过分析策展信号识别主观属性
发明人:Hrishikesh Aradhye 和 Sanketh Shetty
受让人:谷歌有限责任公司
美国专利:11,328,218
授予:2022 年 5 月 10 日
提交日期:2017 年 11 月 6 日
抽象的:
公开了一种用于识别和预测实体(例如媒体剪辑、电影、电视节目、图像、报纸文章、博客条目、个人、组织、商业企业等)的主观属性的系统和方法。
在一个方面,基于对第一媒体项目的反应来识别第一媒体项目的主观属性,并且确定与第一媒体项目有关的个人品质的相关性分数。
使用 (i) 训练输入来训练分类器,该训练输入包括第一媒体项目的一组特征和训练输入的目标输出,目标输出包括第一媒体项目的主观属性的相应相关性分数。
识别和预测实体的主观属性
识别和预测实体(如媒体剪辑、图像、报纸文章、博客条目、个人、组织、商业企业等)的主观属性的方法。
主观属性(例如“可爱”、“有趣”、“真棒”等)被定义,并且特定实体的主观属性根据用户对实体的反应来识别,例如:
- 对网站的评论
- 像!
- 与其他用户共享第一个实体
- Boomarking 第一个实体
- 将第一个实体添加到播放列表
- ETC
确定实体的主观属性的相关性分数
如果主观属性“可爱”出现在视频剪辑的大部分评论中,那么“可爱”可能会获得高相关性分数。
然后将实体与所识别的主观属性和相关性分数相关联(例如通过应用于实体的标签、通过关系数据库表中的条目等)。
对给定实体集合中的每个实体(例如视频剪辑库中的视频剪辑等)执行上述过程,并根据个人素质和相关性分数生成从主观属性到组中实体的逆映射.
然后可以使用逆映射来识别集合中与给定主观属性匹配的所有实体(例如与主观属性“有趣”相关联的所有实体等),从而实现:
- 快速检索相关实体以处理关键字搜索
- 填充播放列表
- 投放广告
- 为分类器生成训练集
- 以此类推
通过提供一组训练示例来训练分类器(例如支持向量机 [SVM]、AdaBoost、神经网络、决策树等),其中训练示例的输入包括从特定实体(例如视频剪辑的特征向量。
它可能包含以下数值:
- 颜色
- 质地
- 强度
- 与视频剪辑关联的元数据标签
- ETC
输出具有特定实体词汇表中每个主观属性的相关性分数。
然后,经过训练的分类器可以预测不在训练集中的实体的主观属性(例如新上传的视频剪辑、尚未收到任何评论的新闻文章等)。
该专利可以根据用户对实体的反应,根据“有趣”、“可爱”等主观属性对实体进行分类。
该专利可以提高实体描述的质量,例如视频剪辑的标签,提高搜索质量和广告定位。
识别主观属性的系统架构
系统架构包括:
- 服务器机器
- 实体店
- 客户端计算机连接到网络
网络可以是公共的(例如互联网)、专用网络(例如局域网(LAN)或广域网(WAN)),或它们的组合。
客户端机器可以是无线终端(智能手机等)、个人计算机(PC)、膝上型计算机、平板计算机或任何其他计算或通信设备。
客户端机器可以运行管理客户端机器的硬件和软件的操作系统(OS)。
浏览器(未示出)可以在客户端机器上(例如在客户端机器的操作系统上)运行。
浏览器可以是可以访问由网络服务器提供的网页和内容的网络浏览器。
客户端机器也可以上传:
- 网页
- 媒体剪辑
- 博客条目
- 文章链接
- 以此类推
服务器机器包括网络服务器和主观属性管理器。 Web 服务器和情绪属性管理器可以运行在不同的设备上。
实体存储是能够存储实体的持久存储,例如媒体剪辑(如视频剪辑、音频剪辑、包含视频和音频的剪辑、图像等)和其他类型的内容项(如网页、文本-基于文档、餐厅评论、电影评论等),以及用于标记、组织和索引实体的数据结构。
实体存储可以由存储设备托管,例如主存储器、基于磁或光存储的磁盘、磁带或硬盘驱动器、NAS、SAN 等。
实体存储可能由网络连接的文件服务器托管。 相反,在其他实施方式中,实体存储可以由某种其他类型的持久性存储器托管,例如服务器机器或通过网络耦合到服务器机器的不同机器的持久性存储器。
存储在实体存储中的实体可能包括由客户端机器上传的用户生成的内容,并且可能包括由服务提供商提供的内容,例如:
- 新闻机构
- 出版商
- 图书馆
- 很快
服务器可以将来自实体商店的网页和内容提供给客户端。
主观属性管理器:
- 根据用户反应识别实体的主观属性(如评论、Like!、分享、书签、播放列表等)
- 确定有关实体的主观属性的相关性分数
- 将主观属性和相关性分数与实体相关联
- 提取颜色、纹理和强度等图像特征等特征; 音频特征,如幅度、频谱系数比率; 文本特征,如词频、平均句子长度、格式参数; 与实体相关的元数据; 等)从实体生成特征向量
- 根据特征向量和主观属性的相关性分数训练分类器
- 使用经过训练的分类器根据新实体的特征向量预测新实体的主观属性
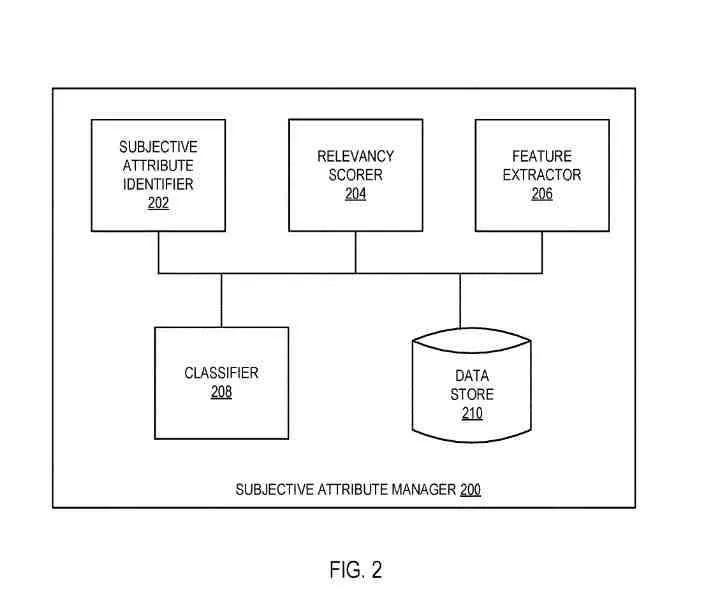
主观属性管理器
主观属性管理器可以与主观属性管理器相同并且可以包括:
- 主观属性标识符
- 相关性评分器
- 特征提取器
- 分类器
- 数据存储
.
这些组件可以组合或分离成更多细节。
数据存储可以与实体存储相同或不同的数据存储(例如临时缓冲区或永久数据存储)来保存个人属性词汇表、要处理的实体、与实体关联的特征向量、个人属性以及与实体相关的相关性分数,或这些数据的某种组合。
数据存储可以由存储设备托管,例如主存储器、基于磁或光存储的磁盘、磁带或硬盘驱动器等。
主观属性管理器通知用户存储在数据存储和实体存储中的信息类型,并允许用户选择不收集这些信息并与主观属性管理器共享。
主观属性标识符
个人属性标识符基于用户对实体的反应来识别实体的主观属性。
个人属性标识符可以通过用户对用户在社交网站上发布的实体的评论的文本处理来识别主观属性。
主观属性标识符可以基于其他类型的用户对实体的反应来识别实体的主观属性,例如:
- '像!' 或“不喜欢!”
- 共享实体
- 为实体添加书签
- 将实体添加到播放列表
- 以此类推
个人属性标识符可以应用阈值来确定哪些属性与实体相关联(例如主观属性应该出现在至少N条评论中等)。
相关性评分器确定关于实体的主观属性的相关性评分。
例如,当主观属性标识符已经基于对发布在社交网络网站上的媒体剪辑的评论识别出主观属性“可爱”、“有趣”和“真棒”时,相关性评分器可以确定这三个主观的每一个的相关性分数属性基于:
- 这些主观属性出现在评论中的频率
- 提供主观属性的特定用户
- 以此类推
例如,如果有 40 条评论,“可爱”出现在 20 条词中,“真棒”出现在 8 条评论中,那么“可爱”可能会获得比“真棒”更高的相关性分数。
可以根据主观属性出现在评论中的比例来分配相关性分数(例如“可爱”的分数为0.5,“真棒”的分数为0.2等)。
相关性评分器可以只保留 k 个最相关的主观属性并丢弃其他个人属性。
例如,假设个人属性标识符标识了在用户评论中出现至少 3 次的七个情感属性。 在这种情况下,例如,相关性评分器可以仅保留具有最高相关性分数的五个主观属性而丢弃其他两个情感属性(例如通过将它们的相关性分数设置为零等)。

相关性分数是介于 0.0 和 1.0(含)之间的自然数。
特征提取器使用以下技术获取实体的特征向量:
- 主成分分析
- 半定嵌入
- 等离子图
- 偏最小二乘
- 以此类推
与提取实体特征相关的计算由特征提取器本身执行。
在其他一些方面,这些计算由另一个实体执行,例如可执行库:
- 由服务器机器托管的图像处理例程[图中未描绘]
- 音频处理例程
- 文本处理例程
- ETC
结果被提供给特征提取器。
分类器是一种学习机器(例如支持向量机 [SVM]、AdaBoost、神经网络、决策树等),它接受与实体相关联的特征向量作为输入并输出相关性分数(例如介于 0 之间的实际数字)和1包括等)个人属性词汇的每个主观属性。
分类器由单个分类器组成。
分类器可以包括多个分类器(如个人属性词汇表中每个主观属性的分类器等)。
为个人属性词汇表中的每个主观属性组装了一组正面示例和负面标准。
主观属性的正例集可以包括与该特定个人属性相关联的实体的特征向量。
主观属性的负面示例集可以包括尚未与该特定个人属性相关联的实体的特征向量。
当正例集和负例集的大小不相等时,可以对更广泛的集进行采样以匹配较小组的大小。
在训练之后,分类器可以通过提供这些实体的特征向量作为分类器的输入来预测不在训练集中的其他实体的主观属性。
通过包括所有具有非零相关性分数的情感属性,可以从分类器的输出中获得一组主观属性。 可以通过将最小阈值应用于数值分数(通过将具有至少例如0.2的分数的所有个人属性视为集合的成员)来获得一组主观分数。
识别实体的主观属性
该方法由可以包括硬件(电路、专用逻辑等)、软件(例如在通用计算机系统或专用机器上运行)或两者的处理逻辑来执行。
该方法由服务器机器执行,而一些其他实现可能由另一个设备执行。
主观属性管理器的各种组件可以在不同的机器上运行(例如个人属性标识符和相关性评分器可以在一个设备上运行,而特征提取器和分类器可以在另一个设备上运行等)。
为了解释的简单起见,该方法被描述为一系列动作。
但是行为可以以各种顺序发生,并且可以与本文未呈现和描述的其他行为一起发生。
此外,并非所有图示的动作都可能需要安装所公开的主题的方法。
此外,本领域技术人员将理解和理解,该方法可以通过状态图或事件表示为一系列相互关联的状态。
此外,应当理解,本说明书中公开的方法能够存储在制造物品上,以方便将这种方法运输和转移到计算设备。
如本文所用,术语制品旨在涵盖可从任何计算机可读设备或存储介质访问的计算机程序。
生成了主观属性的词汇表。
在一些方面,可以定义主观属性词汇。 相反,在其他一些因素中,个人属性词汇可以通过收集用户对实体的反应中使用的术语和短语以自动方式生成。 相反,在其他方面,可以通过手动和自动技术的组合来生成词汇表。
词汇表带有少量预期适用于实体的主观属性。 随着用户反应中出现的更多术语或短语通过对响应的自动处理得到识别,词汇量会随着时间的推移而扩大。
主观属性词汇可以分层组织,可能基于与个人属性相关的“元属性”(例如个人属性“有趣”可能具有元属性“正面”,而主观点“恶心”可能具有元属性“负面”等)。
对一组实体(如实体存储中的所有实体、实体存储中的实体子集等)进行预处理。
在一方面,实体的预处理包括识别用户对实体的反应,然后基于这些反应训练分类器。
当实体是实际的物理实体时
应该注意的是,当实体是实际的物理实体(例如人、餐厅等)时,实体的预处理通过与物理实体关联的“网络代理”(例如社交网站上演员的粉丝页面、网站上的餐厅评论等); 但是,主观属性被认为与实体本身相关联(例如演员或餐厅,而不是演员的粉丝页面或餐厅评论)。
详细描述了用于执行get的方法的示例。
Atn 接收到不在集合 S 中的实体 E(例如新上传的视频片段、尚未收到任何评论的新闻文章、实体存储中未包含在训练集中的实体等)。
获得实体 E 的主题属性和相关性分数。
下面详细描述第一示例方法的实现,并且描述第二示例方法的性能。
获得的主观属性和相关度得分与实体E相关联(例如通过对实体应用相应的标签,在关系数据库表中添加记录等)。
执行继续返回。
应该注意的是,分类器可以通过可能同时执行的重新训练过程重新训练(例如在循环的每 100 次迭代之后,每 N 天等)。
预处理一组实体
该方法由可以包括硬件(电路、专用逻辑等)、软件(例如在通用计算机系统或专用机器上运行)或两者的处理逻辑来执行。
该方法被执行,而在一些其他实现中可能由另一台机器执行。
训练集被初始化为空集。 实体 E 被选中并从实体集合 S 中移除。
实体 E 的主观属性是基于用户对实体 E 的反应(例如用户评论、Like!、书签、共享、添加到播放列表等)来识别的。
主观属性的识别包括对用户评论进行处理,例如:
- 将用户评论中的单词与词汇表中的主观属性进行匹配
- 结合词匹配和其他自然语言处理技术,如句法和语义分析
- ETC
位置附近出现的实体
对于发生在许多位置的实体,用户反应可能会被汇总,例如:
- 出现在许多用户的播放列表中的实体
- 已被共享并出现在社交网站上多个用户的“新闻源”中的实体
- ETC
不同位置可能会根据各种因素对相关性分数的贡献进行加权,例如:
与该位置相关联的特定用户(例如,特定用户可能是古典音乐的权威,因此在他们的新闻源中对实体的评论可能比在另一个新闻源中的评论获得更多权重等)、非文本用户反应(例如如“喜欢!”、“不喜欢!”、“+1”等)。
此外,实体出现的位置数量也可用于确定主观属性和相关性分数(例如,当视频剪辑在数百个用户播放列表中时,视频剪辑的相关性分数可能会增加等)。
该块由主观属性标识符执行。
主观属性的相关性分数由实体 E 确定。
根据个人属性在用户评论中出现的频率、在其话语中提供主观细节的特定用户(例如某些用户可能从经验中知道在他们的评论比其他用户等)。
例如,如果有 40 条评论,“可爱”出现在 20 条词中,“真棒”出现在 8 条评论中,那么“可爱”可能会获得比“真棒”更高的相关性分数。
相关性分数可以根据出现主观属性的评论的比例来分配(例如“可爱”的分数为0.5,“真棒”的分数为0.2等)。
在一方面,相关性分数被归一化以落在区间 [0, 1] 内。
通过一些方面,可以基于它们的相关性分数来丢弃所识别的主观属性(例如保留具有最高相关性分数的k个情感属性,丢弃任何相关性分数低于阈值的个人属性等)。
应该注意,在某些方面,可以通过将其相关性分数设置为零来丢弃主观属性。
主观属性和相关性分数与实体相关联
主观属性和相关性分数与实体相关联(例如通过标记、关系数据库中表中的条目等)。
获得实体 E 的特征向量。
一方面,视频剪辑或静止图像的特征向量可以包含关于颜色、纹理、强度等的数值,而音频剪辑(或有声音的视频剪辑)的特征向量可以包含关于幅度的数值,光谱系数等,而文本文档的特征向量可能包括:
- 关于词频的数值
- 平均句子长度
- 格式化参数
- 以此类推
这可以由特征提取器执行。
获得的特征向量和相关性分数被添加到训练集中。
块检查实体集合 S 是否为空; 如果 S 非空,则继续执行,否则继续执行。
分类器在训练集的所有示例上进行训练,以便将训练示例的特征向量作为输入提供给分类器,并将主观属性相关性分数作为输出提供。
获取实体的主观属性和相关性分数
生成实体 E 的特征向量。
如上所述,视频剪辑或静止图像的特征向量可以包含关于颜色、纹理、强度等的数值。相反,音频剪辑(或有声音的视频剪辑)的特征向量可以包括数值关于幅度、频谱系数等。相比之下,文本文档的特征向量可以包括关于词频、平均句子长度、格式参数等的数值。
训练后的分类器提供特征向量来获得实体 E 的预测主观属性和相关性分数。
预测的主观属性和相关性分数与实体 E 相关联(例如通过应用于实体 E 的标签、通过关系数据库表中的条目等)。
获取实体主观属性和相关性分数的第二种方法
该方法由处理逻辑执行,该处理逻辑可以包括硬件(电路、专用逻辑等)、软件或两者的组合。
该方法由服务器机器执行,而其他一些方法可能由另一个设备执行。
生成实体 E 的特征向量。 训练后的分类器提供特征向量来获得实体 E 的预测主观属性和相关性分数。
获得的预测主观属性被建议给用户(例如上传实体的用户。从用户那里获得一组细化的个人属性,例如通过用户从建议属性中选择的网页,并且可能添加新属性等)。
实体的默认相关性分数
默认的相关性分数被分配给用户添加的任何新的主观属性。
默认相关性分数可能是 1.0,范围从 0.0 到 1.0,默认相关性分数可以基于特定用户(例如,当从过去的历史中知道用户非常擅长建议属性时,分数为 1.0,分数0.8 当用户被认为有点擅长建议属性等时)。
Block 分支基于用户是否删除了任何建议的主观属性(例如不选择属性)。
实体 E 被存储为已移除属性的负面示例,以供将来重新训练分类器。 精炼的主观属性集和相应的相关性分数与实体 E 相关联(例如通过应用于实体 E 的标签、通过关系数据库表中的条目等)。