
NLU 引擎基准测试:面向 AI 市场领导者的数据驱动方法
已发表: 2022-09-09自然语言理解 (NLU) 引擎是巨大的客户情绪驱动因素。 AI 和 NLU 发展得如此之快,以至于一名谷歌员工声称该公司的聊天机器人 LaMDA 是一个有自我意识的人,从而引起了全球的关注。
但别担心。 我们不是来用人工智能机器人接管世界的故事或客户服务来吓唬你的。
大约71% 的美国消费者在他们的客户服务对话中仍然更喜欢人性化,这就是基准 NLU 引擎进入画面的地方。
NLU 可以通过在客户交互中添加知识、上下文和情感层来帮助座席更好地理解和服务客户。 在基准 NLU 引擎的支持下,对话式 AI 让品牌变得更加智能和善解人意,并发现隐藏的客户线索,使客户服务更加个性化,不像机器。
但是,您如何对 NLU 引擎进行基准测试以评估其 AI 能力? 要到达那里,让我们首先了解关键技术术语。
NLU 引擎基准测试词汇表
对话式人工智能
对话式 AI是一种 NLU 支持的功能,它使计算机和数字应用程序能够通过识别人类对话背后的情感、紧迫性和上下文来吸引客户。数据集
数据集是计算机可以将其作为单个信息集处理的相关信息集的集合。发声
话语是通过文本、音频或视频接收到的用户语音的短语或句子。 NLU 引擎使用话语来训练、测试和解释用户意图。意图
意图表示用户在动作、事件或语句背后的目标。 例如,用户操作可以分类为产品查询、投诉、退款请求等。准确性
准确率是 NLU 引擎与正确意图匹配的测试句子的百分比。F1 宏
每个意图的精度和召回率的宏观平均值的调和平均值称为 F1 宏。
精度= 对意图的真阳性结果的数量/对意图的所有阳性结果。
召回率 = 对意图的真阳性结果数/被确定为对意图阳性的结果数。
NLU 引擎基准测试:了解流程
比较 NLU 引擎可能是一个乏味的过程。 将一组支持 NLU 的解决方案列入候选名单并进行练习以测试在您的客户中观察到的常见意图可能会很耗时。 这就是由研究支持的结构化方法派上用场的地方,可以用无偏见的方法评估 NLU 引擎及其AI 直觉能力。
用于构建会话代理的自然语言理解服务基准测试
这种 NLU 基准测试方法比较家庭自动化机器人数据集上的 NLU 引擎,将其分解为小型和大型数据集,以评估不同训练和测试数据大小的机器学习准确性。
NLU 基准测试方法中使用的方法
小数据集
随机选择 64 个不同的意图
每个意图使用 10 个例句来训练 NLU 引擎
测试了 1,076 个例句(不属于训练集)
大型数据集
为大型数据集挑选了上述相同的 64 个意图
每个意图使用大约 30 个例句来训练 NLU 引擎
测试了 5,518 个例句(不属于训练集)
NLU 引擎基准测试报告:结果
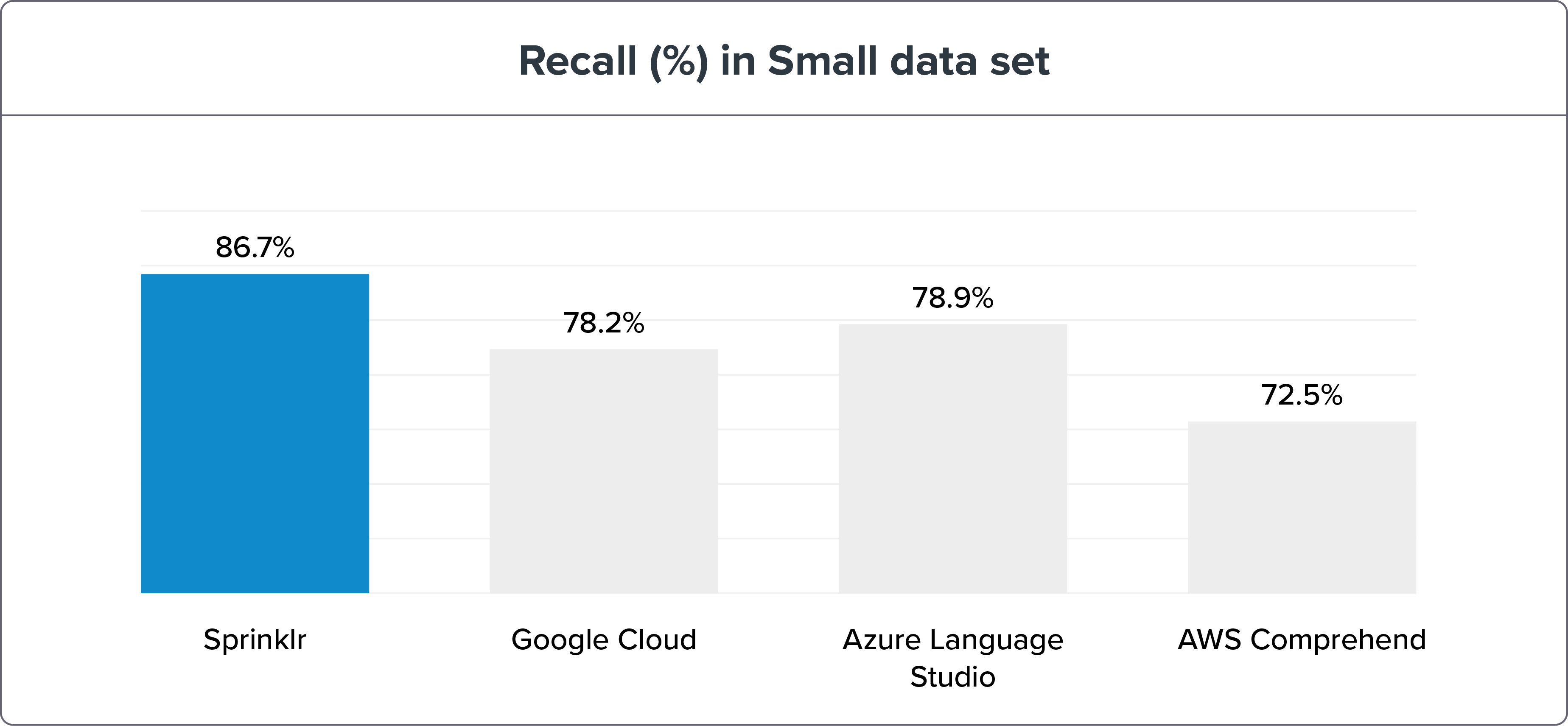
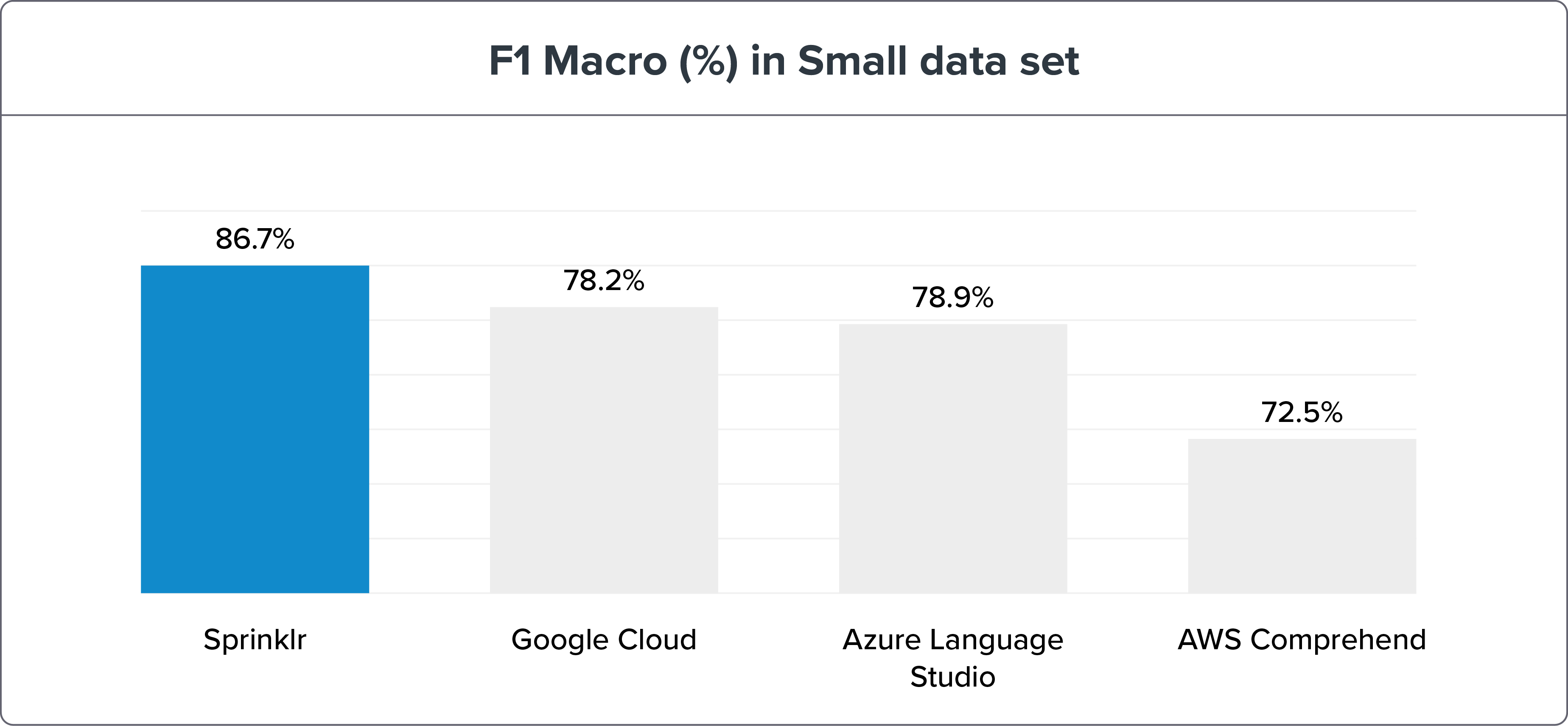
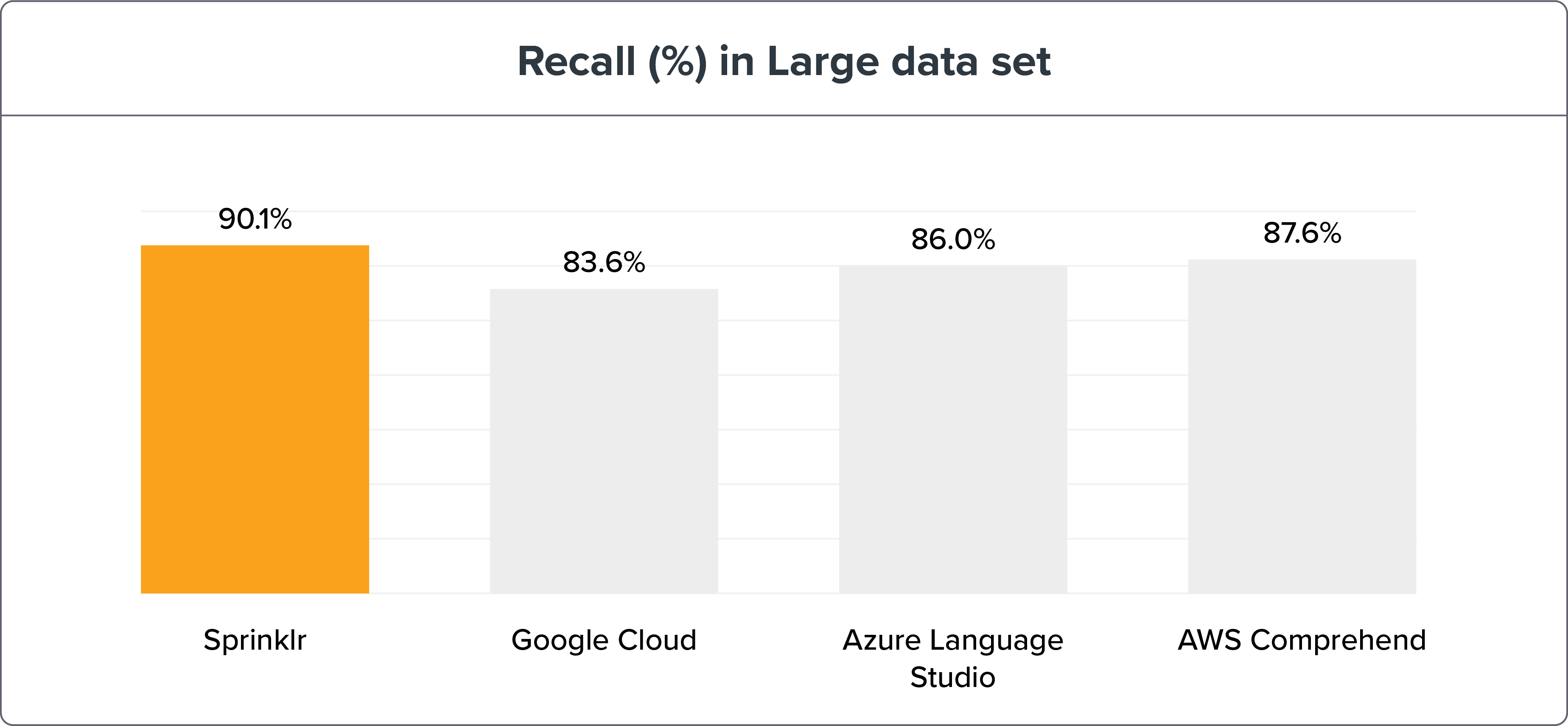
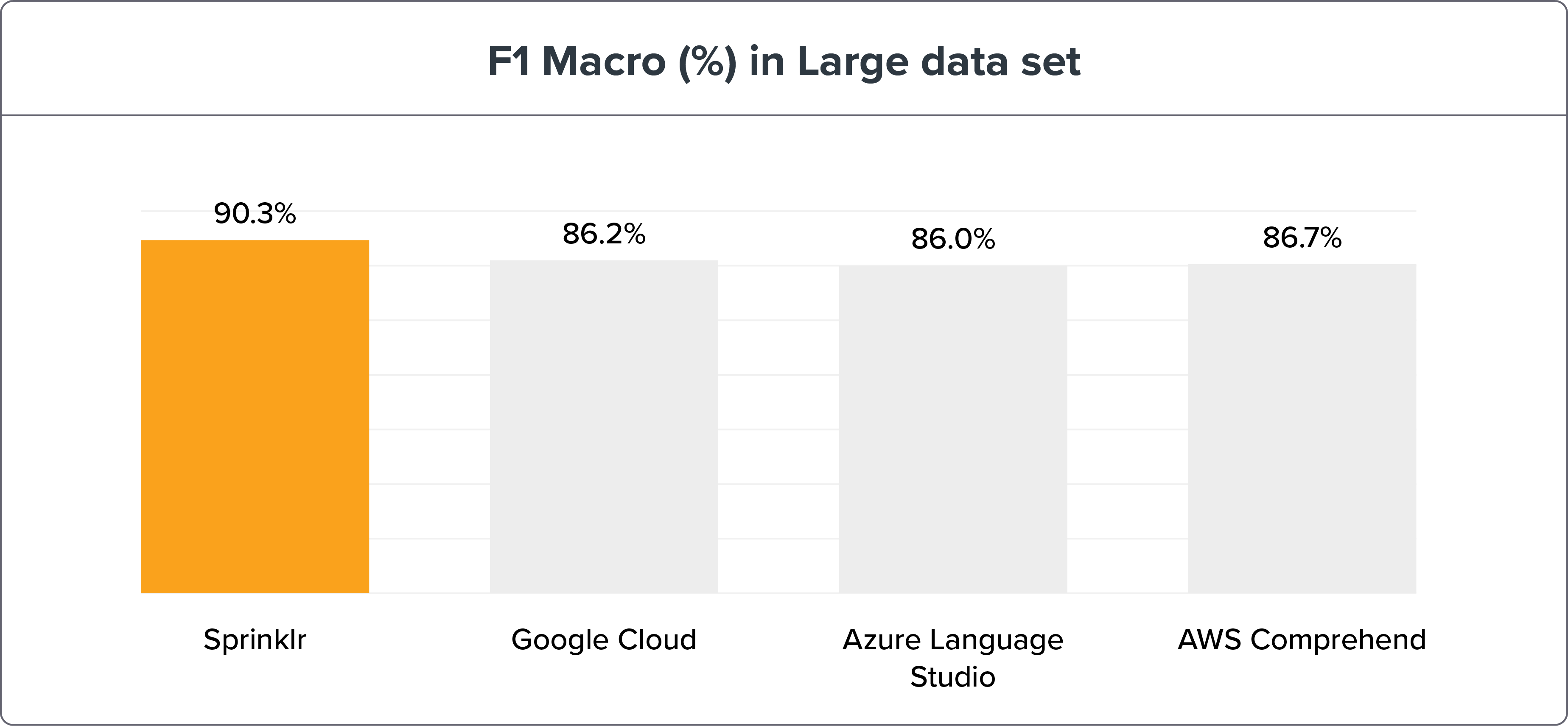
NLU 基准测试方法显示 Sprinklr 的 NLP 准确性凭借召回和 F1 宏远高于其同时代产品——谷歌云、Azure 语言工作室和 AWS Comprehend。 可以在此处找到基准测试数据和结果。
如果我们将 NLU 引擎基准测试分解为小型和大型数据集,Sprinklr NLU 引擎仍然是明显的赢家。
注意:更大的数据集是测试和训练意图以获得更高准确性的最佳方式。 但是 Sprinklr 的 NLU 引擎的精度变化只有 ≤ 3%。
小数据集
参数:
640 个训练句子 = 每个 Intent 10 个句子
1,076 个测试句子
大型数据集
参数:
1,908 个训练句子 ≈ 每个 Intent 30 个句子
5,518 个测试句子
Sprinklr 成为 NLU 引擎基准测试的明显赢家
Sprinklr 的 NLU 引擎在确定查询意图时保持一致和准确,测试输入和训练输入之间的映射更好。
示例 1:小型数据集
问:有什么需要注意的吗
基本事实:calendar_query

示例 2:大型数据集
查询:欧盟有多少个国家
基本事实:qa_factoid

NLU 引擎基准测试的局限性
数据集的大小:由于使用了大量经过充分研究的数据集,NLU 引擎可能比通常发现的原始结构化数据更快地从测试话语中学习。

使用的语言:仅使用英语来测试不同的实例和意图。
测试数据的性质:用户的话语听起来可能不像典型的客户,他们可能会犯更多的语法错误并有对话间隙。
最常见的 NLU 引擎解释挑战
典型的 NLU 引擎具有一定的局限性,尤其是在解释客户交互时。 以下是最常见的 NLU 引擎解释错误以及避免它们的策略:
讽刺
NLU 引擎很难检测出讽刺或消极攻击性的客户评论。
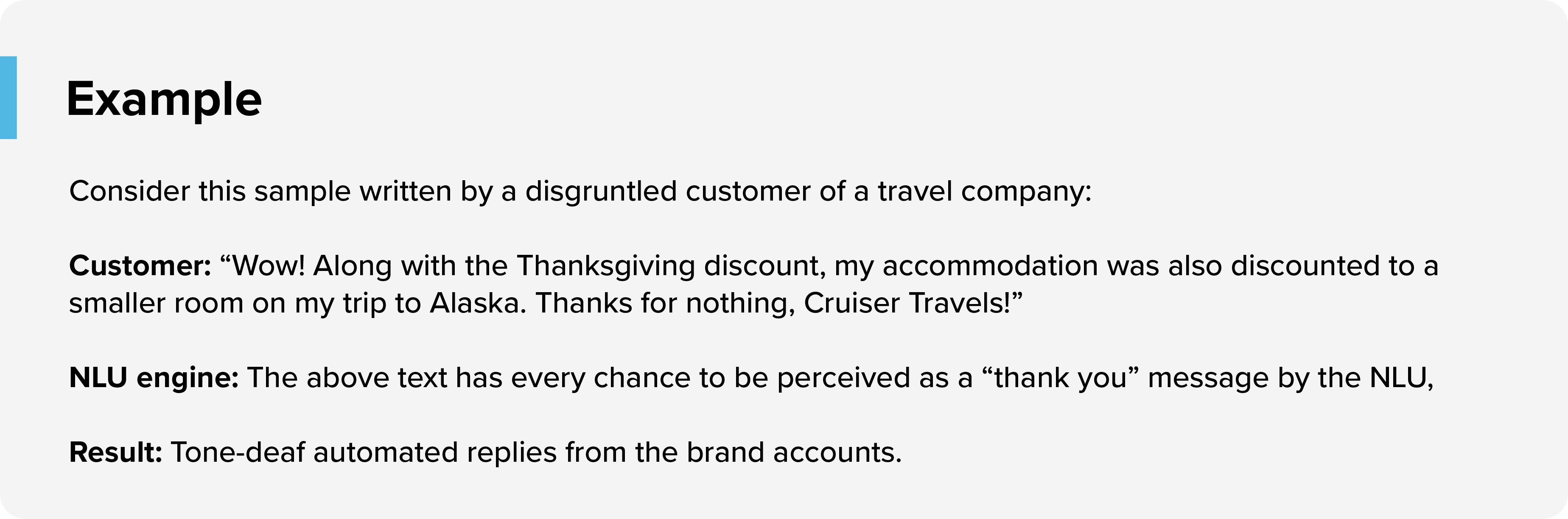
如何解决它:克服这个问题的一种方法是在批准自动 NLU 引擎响应之前添加关键字,例如“谢谢,哇,随便什么”,以通过代理运行。
歧义
有时,人类很难区分句子中的一个词是用作名词、动词还是形容词。 “hang on”或“put out”等短语动词也会影响 NLU 引擎的认知。
如何解决:减少歧义的最好方法是继续训练 NLU 引擎来处理歧义的句子和短语。 随着时间的推移,引擎开始通过将测试输入与真实的用户交互进行比较来从测试输入中学习。
在 NLU 引擎和 AI 聊天机器人中减少歧义的其他方法:
利用机器学习模型进行更好的 NLU 训练:使用上下文相关的机器学习模型,例如来自 Transformers (BERT) 的双向编码器表示和来自语言模型 (ELMo) 的嵌入来训练您的 NLU 引擎。 这些AI 模型考虑了单词和句子的所有不同表示,并使用额外的文本来填充模棱两可的用户条目。
创建适当的提示以仔细检查语言不确定性:使您的 NLU 引擎能够提供“消歧”响应,提示用户从不止一种可能性中选择正确版本的文本。 这与 Google 的“您的意思是……”提示非常相似,其中包含您的搜索词的可能变体。
训练和训练更多:严格训练您的 NLU 引擎以将信号与噪声分离。 没有比使用各种独特的数据集训练 NLU 引擎更好的意图检测的捷径。 用户请求可能包含影响 NLU 引擎意图标记能力的单词和句子结构。

语言错误
拼写错误和不正确的句子结构会阻止 NLU 引擎准确识别用户意图。 虽然语法检查可以解决基本错误,但俚语和口语很难解释,尤其是在文本到语音和语音分析中。
如何解决:再一次,克服这个问题的关键是向 NLU 引擎提供大量不准确的模拟话语,其中充满了错误和错误的语言。
域变体
Domain-speak 是另一个不同行业的领域。 医疗保健中的“文档”可以不同于技术中的“文档”工作流程。
如何解决:明确定义意图层次结构可以帮助您的 NLU 引擎确定与客户响应或话语相关联的行业或领域。
表征顶级 NLU 引擎的品质
NLU 引擎的认知能力只是为您的公司评估它们时要考虑的因素之一。 它有助于克服阻碍大规模理解用户意图的繁琐手动工作。
此外,以下是 NLU 引擎中需要注意的一些更重要的品质:
1.速度
NLU 引擎必须快速上交结果,因为对话式 AI 是关于了解客户意图以快速准确地做出响应。 处理客户交互的速度不应降低 NLU 引擎的意图检测准确性。
2.垂直化
NLU 引擎有大量的用例,横跨技术、零售、电子商务、物流和酒店等行业。 对话式 AI 功能应该能够区分这些行业,并以独特的方法适应每个解决方案领域。
3. 易用性
寻找包含非技术员工资料的 NLU 引擎。 了解如何测试和训练数据集不应仅限于质量保证工程师和开发人员。 这是非技术背景的企业主可以自己做的事情。 由无代码 NLU 引擎提供支持的对话式 AI 是提高采用率和可用性的方法。
4. 可扩展性
随着 NLU 引擎收集越来越多的数据输入,它必须在各种区域语义、语言变化和用户表达的不同实体中训练自己。 构建一个 NLU 框架,该框架可以处理多种语言并使您的对话式 AI 聊天机器人面向未来。
是什么让 Sprinklr 的 NLU 引擎成为对话式 AI 的市场领导者?
Sprinklr 的 AI 引擎专门用于理解和情境化整个客户体验管理范围。 以下是 Sprinklr AI 与传统对话式 AI 平台不同的七个区别:
1.准确的消息分类
自动阅读、破译和分析客户信息,将它们分类为意图,并定义内部团队以进行准确的案例分配。
2. 勤奋的危机检测
当客户交互失控时,使用预先确定的参数(例如负面品牌提及和关键字)或 AI 识别的痛苦迹象(例如情绪检测)触发警报。
3. 情境感知虚拟协助
根据可用的客户数据、知识库和跨渠道交互历史,生成对客户的自动响应或向代理提供 AI 帮助。
4. 面向未来的预测分析
不仅可以预见客户服务,还可以预见市场趋势,例如热门话题、宏观经济、消费者情绪、公关危机和不断变化的行业基准,以重新调整您的产品和营销路线图。 Sprinklr 的 AI 可以通过上下文数据细分识别跨数字渠道、客户人口统计等的模式。

5. 智能视觉解读
处理品牌和客户交互中涉及的视觉数据,以在没有人工代理的情况下准确定义图像和视频。
6.端到端AI工作室
在 Sprinklr 中训练、测试和部署 AI 模型,以实现更好的社交聆听、消息分类、对话式 AI 和聊天机器人、响应自动化和自助社区。
7.品牌互动节制
监控每一次座席与客户的互动,以确保遵守内部品牌指南,并生成报告以确定提高客户满意度 (CSAT) 和减少主要联系驱动因素的改进领域。
您想通过零接触个性化和运营效率来扩展您的客户支持吗? Sprinklr 的 NLU 引擎可以成为您需要的桥梁——它带有数百万个 AI 预测、数据点和数百个可立即部署的 AI 模型。
开始免费试用 Modern Care Lite
了解 Sprinklr 如何使用基础 AI 帮助企业在 13 个以上的渠道上提供优质体验,以便您可以在整个客户体验中倾听、路由、解决和衡量。