
Noindex Nofollow 和 Disallow:搜索爬虫指令
已发表: 2022-12-01您可以使用三个指令(命令)来指示搜索引擎如何从您的站点中发现、存储和提供信息作为搜索结果:
- NoIndex:不要将我的页面添加到搜索结果中。
- NoFollow:不要查看此页面上的链接。
- 不允许:根本不要看这个页面。
这些指令允许您控制哪些网站页面可以被搜索引擎抓取并出现在搜索中。
没有索引是什么意思?
noindex 指令告诉搜索爬虫,如 googlebot,不要在其搜索结果中包含网页。

你如何标记页面NoIndex?
有两种方法可以发出noindex指令:
- 将 noindex 元标记添加到页面的 HTML 代码中
- 在 HTTP 请求中返回一个 noindex 标头
通过为页面使用“无索引”元标记,或作为 HTTP 响应标头,您实际上是在搜索中隐藏该页面。
noindex指令也可用于仅阻止特定的搜索引擎。 例如,您可以阻止 Google 将某个页面编入索引,但仍允许 Bing:
示例:阻止大多数搜索引擎*
<meta name=”robots” content=”noindex”>
示例:仅阻止 Google
<meta name=”googlebot” content=”noindex”>
请注意:自 2019 年 9 月起, Google 不再遵守 robots.txt 文件中的 noindex 指令。 Noindex 现在必须通过 HTML 元标记或 HTTP 响应标头发布。 对于更高级的用户, disallow目前仍然有效,但并非适用于所有用例。
noindex 和 nofollow 有什么区别?
这是存储内容和发现内容之间的区别:
noindex在页面级别应用,并告诉搜索引擎爬虫不要在搜索结果中索引和提供页面。
nofollow应用于页面或链接级别,并告诉搜索引擎爬虫不要跟踪(发现)链接。
本质上,noindex 标记从搜索索引中删除了一个页面,而 nofollow 属性从搜索引擎的链接图中删除了一个链接。
NoFollow 作为页面属性
在页面级别使用 nofollow 意味着爬虫不会跟踪该页面上的任何链接来发现其他内容,并且爬虫不会将这些链接用作目标站点的排名信号。
<meta name=”robots” content=”nofollow”>
NoFollow 作为链接属性
在链接级别使用 nofollow 可防止爬虫探索广告特定链接,并防止该链接被用作排名信号。
nofollow 指令使用 href 标签内的 rel 属性应用于链接级别:
<a href=”https://domain.com” rel=”nofollow”>
特别是对于 Google,使用 nofollow 链接属性将阻止您的站点将 PageRank 传递到目标 URL。
为什么要将页面标记为 NoFollow?
对于大多数用例,您不应将整个页面标记为 nofollow——将单个链接标记为 nofollow 就足够了。
如果您不希望 Google 查看页面上的链接,或者您认为页面上的链接可能会损害您的网站,则可以将整个页面标记为nofollow 。
在大多数情况下,当您无法控制发布到页面的内容(例如:用户生成的内容可以发布到页面)时,会使用一揽子页面级nofollow指令。
一些高端出版商也一直在他们的页面上全面应用 nofollow 指令,以阻止他们的作者在他们的内容中放置赞助商链接。
如何使用 NoIndex 页面?
将不太可能为用户提供价值且不应显示为搜索结果的页面标记为无索引。 例如,用于分页的页面不太可能随着时间的推移在其上显示相同的内容。
Domain.com/category/resultspage=2不太可能向用户显示比domain.com/category/resultspage=1更好的结果,并且这两个页面只会在搜索中相互竞争。 最好不要索引唯一目的是分页的页面。
以下是您应该考虑不编制索引的页面类型:
- 用于分页的页面
- 内部搜索页面
- 广告优化着陆页
- 例如:只显示推销和注册表单,没有主导航
- 例如:相同内容的重复变体,仅用于广告
- 存档的作者页面
- 结帐流程中的页面
- 确认页
- 例如:感谢页面
- 例如:订购完整的页面
- 例如:成功! 页数
- 一些与您的网站无关的插件生成的页面(例如:如果您使用商务插件但不使用其常规产品页面)
- 管理页面和管理登录页面
标记页面 Noindex 和 Nofollow
标记为 noindex 和 nofollow 的页面将阻止爬虫索引该页面,并阻止爬虫探索页面上的链接。
基本上,下图展示了搜索引擎将根据您使用 noindex 和 nofollow 指令的方式在网页上看到的内容:

将已编入索引的页面标记为 NoIndex
如果搜索引擎已经为某个页面编制了索引,并且您将其标记为noindex ,那么下次抓取该页面时,它将从搜索结果中删除要使这种从索引中删除页面的方法起作用,您不得使用 robots.txt 文件阻止(禁止)爬虫。
如果您告诉爬虫不要读取该页面,它永远不会看到noindex标记,并且该页面将保持索引状态,尽管其内容不会被刷新。
如何阻止搜索引擎索引我的网站?
如果你想从搜索索引中删除一个页面,在它已经被索引后,你可以完成以下步骤:
- 应用 noindex 指令将 noindex 属性添加到元标记或 HTTP 响应标头
- 请求搜索引擎抓取页面对于 Google,您可以在搜索控制台中执行此操作,请求 Google 重新索引该页面。 这将触发 Googlebot 抓取页面,Googlebot 将在其中发现 noindex 指令。您需要为要删除页面的每个搜索引擎执行此操作。
- 确认页面已从搜索结果中删除 请求爬虫重新访问您的网页后,给它一些时间,然后确认您的页面已从搜索结果中删除。 您可以通过转到任何搜索引擎并输入站点冒号目标 url 来执行此操作,如下图所示。
如果您的搜索没有返回任何结果,那么您的网页已从该搜索索引中删除。 - 如果页面尚未删除检查您的 robots.txt 文件中是否没有“禁止”指令。 如果不允许Google和其他搜索引擎抓取该页面,则无法读取noindex指令。如果读取,请删除目标页面的disallow指令,然后重新请求抓取。
- 在 robots.txt 文件中为目标页面设置禁止指令Disallow: /page$
您需要将美元符号放在 robots.txt 文件中 URL 的末尾,否则您可能会不小心禁止该页面下的任何页面以及以相同字符串开头的任何页面。 例如: Disallow: /sweater也会禁止 /sweater-weather 和 /sweater/green,但是Disallow: /sweater$只会禁止确切的页面 /sweater。
如何从 Google 搜索中删除页面
如果您要从搜索中删除的页面位于您拥有或管理的网站上,则大多数网站都可以使用网站管理员 URL 删除工具。

网站管理员 URL 删除工具只会从搜索中删除大约 90 天的内容,如果您想要更持久的解决方案,您需要使用 noindex 指令,禁止从您的 robots.txt 中抓取,或者从您的站点中删除该页面。 Google 在此处提供了有关永久删除 URL 的附加说明。
如果您尝试从不属于您的网站的搜索中删除网页,您可以请求 Google 从搜索中删除符合以下条件的网页:
- 显示个人信息,例如您的信用卡或社会安全号码
- 该页面是恶意软件或网络钓鱼计划的一部分
- 该页面违反了法律
- 该页面侵犯了版权
如果页面不符合上述条件之一,您可以联系 SEO 公司或 PR 公司寻求在线声誉管理方面的帮助。
你应该不索引类别页面吗?
通常不建议不索引类别页面,除非您是企业级组织,以编程方式根据用户生成的搜索或标签旋转类别页面并且重复内容变得笨拙。
在大多数情况下,如果您智能地标记您的内容,以帮助用户更好地浏览您的站点并找到他们需要的内容的方式,那么您会没事的。
事实上,类别页面可以成为 SEO 的金矿,因为它们通常在类别主题下显示内容的深度。
看看我们在 2018 年 12 月所做的分析,以量化一些在线出版物的类别页面的价值。
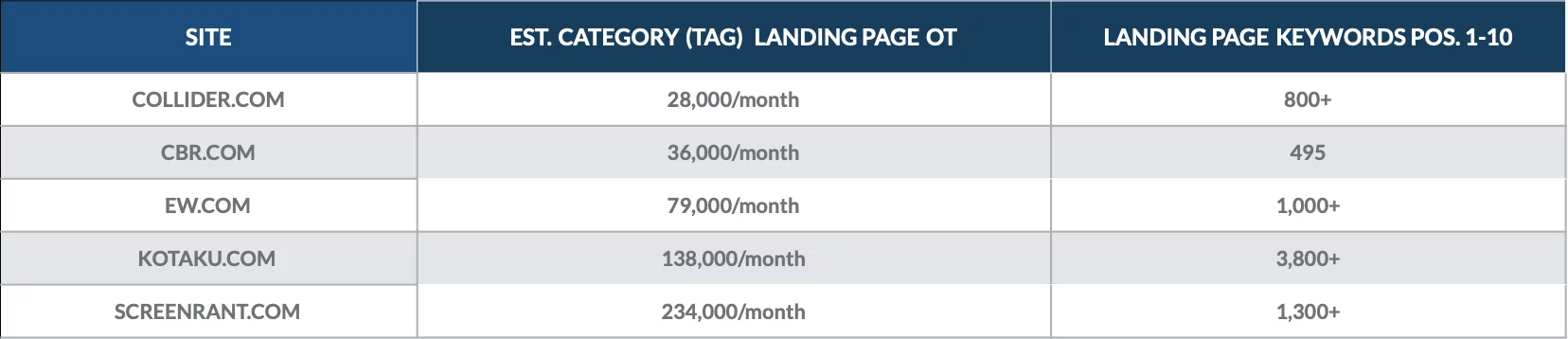
我们发现类别着陆页为数百个第 1 页关键字排名,并且每月带来数千名有机访问者。
每个站点最有价值的类别页面通常都会带来数以千计的自然访问者。
看看下面的 EW.com,我们测量了每个页面的流量(用圆圈的大小表示)和每个页面的流量值(用圆圈的颜色表示)。
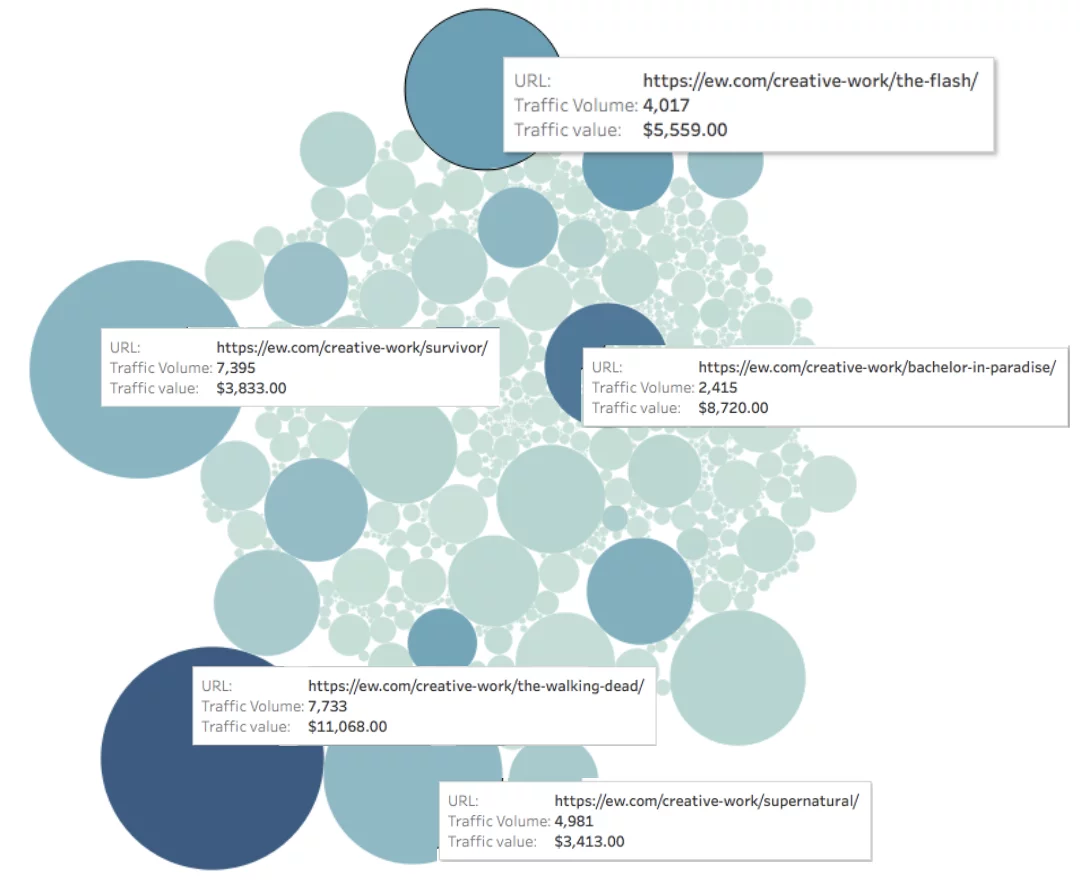
页面的每月有机价值 = 颜色深度
现在想象一下相同的图表,但对于访问者可能会主动购买的基于产品的网站。
话虽如此,如果您的类别相似到足以导致用户混淆或在搜索中相互竞争,那么您可能需要进行更改:
- 如果您自己设置类别,那么我们建议将内容从一个类别迁移到另一个类别,并减少您总体上拥有的类别总数。
- 如果您允许用户旋转类别,那么您可能希望不索引用户生成的类别页面,至少在新类别经过审查过程之前。
如何阻止 Google 索引子域?
有几个选项可以阻止 Google 索引子域:
- 您可以使用 .htpasswd 文件添加密码
- 您可以使用 robots.txt 文件禁止爬虫
- 您可以向子域中的每个页面添加 noindex 指令
- 您可以 404 所有子域页面
添加密码以阻止索引
如果您的子域用于开发目的,那么将 .htpasswd 文件添加到子域的根目录是一个完美的选择。 登录墙将阻止爬虫索引子域上的内容,并防止未经授权的用户访问。
示例用例:
- 开发域名.com
- 登台.domain.com
- 测试.domain.com
- QA.domain.com
- UAT.domain.com
使用 robots.txt 阻止索引
如果您的子域用于其他目的,那么您可以将 robots.txt 文件添加到子域的根目录。 然后应该可以按如下方式访问它:
https://subdomain.domain.com/robots.txt
您需要将 robots.txt 文件添加到您试图阻止搜索的每个子域。 例子:
https://help.domain.com/robots.txt
https://public.domain.com/robots.txt
在每种情况下,robots.txt 文件都应禁止爬虫,要使用单个命令阻止大多数爬虫,请使用以下代码:
用户代理: *
不允许: /
user-agent:之后的星号*称为通配符,它将匹配任何字符序列。 使用通配符将向所有用户代理发送以下禁止指令,无论其名称如何,从 googlebot 到 yandex。
反斜杠告诉爬虫该子域的所有页面都包含在禁止指令中。
如何有选择地阻止子域页面的索引
如果您希望子域中的某些页面出现在搜索中,而不是其他页面,您有两种选择:
- 使用页面级 noindex 指令
- 使用文件夹或目录级别的禁止指令
页面级别的 noindex 指令实施起来会更麻烦,因为该指令需要添加到每个页面的 HTML 或页眉中。 但是,noindex 指令将阻止 Google 索引子域,无论该子域是否已被索引。
目录级禁止指令更容易实现,但只有在子域页面不在搜索索引中时才会起作用。 只需更新子域的 robots.txt 文件即可禁止抓取适用的目录或子文件夹。
我怎么知道我的页面是否没有索引?
不小心在您的网站上添加无索引指令页面可能会对您的搜索排名和搜索可见性造成严重后果。
如果您发现某个页面尽管有良好的内容和反向链接但没有看到任何自然流量,请首先抽查您是否不小心从 robots.txt 文件中禁止了抓取工具。 如果这不能解决您的问题,您需要检查各个页面是否有 noindex 指令。
检查 WordPress 页面上的 NoIndex
WordPress 可以轻松地在您的页面上添加或删除此标签。 检查页面上是否存在 nofollow 的第一步是简单地切换“设置”菜单的“阅读”选项卡中的“搜索引擎可见性”设置。
这可能会解决问题,但此设置只是作为“建议”而不是规则,而且您的某些内容可能最终会被编入索引。
为了确保您的文件和内容的绝对隐私,您必须采取最后一步,或者使用 cPanel 管理工具(如果可用)或通过一个简单的插件对您的站点进行密码保护。
同样,可以通过删除密码保护并取消选中可见性设置来从您的内容中删除此标签。
检查 Squarespace 上的 NoIndex
使用平台的代码注入功能,Squarespace 页面也很容易被 NoIndexed。 与 WordPress 一样,Squarespace 可以使用密码保护轻松阻止常规搜索,但是该平台还建议不要采取此步骤来保护内容的完整性。
通过在您希望对 Internet 搜索引擎隐藏的每个页面及其下面的每个子页面中添加 NoIndex 代码行,您可以确保应禁止公众访问的受保护内容的安全。 与其他平台一样,删除此标签也相当简单:只需使用代码注入功能将代码取回即可。
Squarespace 的独特之处在于其竞争对手主要将此选项作为页面管理工具中设置套件的一部分提供。 Squarespace 从这里出发,允许对代码进行个人操作。 这很有趣,因为您能够看到您对页面内容所做的更改,这与此空间中的其他内容不同。
在 Wix 上检查 NoIndex
Wix 还可以简单快速地修复 NoIndexing 问题。 在“菜单和页面”设置中,如果您想在您的站点中对单个页面进行 NoIndex,则只需停用“在搜索结果中显示此页面”选项即可。
与其竞争对手一样,Wix 还建议使用密码保护您的页面或整个网站,以提供额外的隐私。 然而,Wix 与其他支持团队的不同之处在于,支持团队不会在两个方面规定并行操作以保护爬虫的内容。 Wix 特别说明了从菜单中隐藏页面和从搜索条件中隐藏页面之间的区别。
对于经验不足的网站建设者来说,这是特别有用的建议,考虑到从您的网站菜单中删除会导致无法从网站访问该页面,而不是通过谨慎的 Google 搜索词,他们最初可能不了解其中的区别。