
什么是抓取预算以及如何以智能方式对其进行优化?
已发表: 2021-08-19目录
抓取预算分析是任何 SEO 专家的工作职责之一(特别是如果他们正在处理大型网站)。 一项重要的任务,在谷歌提供的材料中得到了很好的介绍。 然而,正如你在 Twitter 上看到的那样,即使是谷歌员工也淡化了抓取预算在获得更好的流量和排名方面的作用:

他们对这个正确吗?
Google 如何工作和收集数据?
当我们提出这个话题时,让我们回顾一下搜索引擎是如何收集、索引和组织信息的。 在您以后在网站上的工作中,将这三个步骤牢记在心是必不可少的:
第 1 步:爬行。 搜索在线资源,目的是发现和浏览所有现有的链接、文件和数据。 通常,Google 从网络上最受欢迎的地方开始,然后继续扫描其他不太流行的资源。
第 2 步:索引。 Google 会尝试确定该页面的内容以及所分析的内容/文档是否构成独特或重复的材料。 在这个阶段,谷歌对内容进行分组并建立重要性顺序(通过阅读rel=”canonical”或rel=”alternate”标签中的建议或其他方式)。
第 3 步:上菜。 一旦被分割和索引,数据就会显示出来以响应用户查询。 这也是谷歌通过考虑用户位置等因素对数据进行适当排序的时候。
重要提示:许多可用材料忽略了第 4 步:内容渲染。 默认情况下,Googlebot 会将文本内容编入索引。 然而,随着网络技术的不断发展,谷歌不得不设计新的解决方案来停止“阅读”并开始“看到”。 这就是渲染的全部内容。 它服务于谷歌,以显着提高其在新推出的网站中的影响力并扩大索引。
注意:内容呈现问题可能是爬网预算失败的原因。
抓取预算是多少?
抓取预算只不过是抓取工具和搜索引擎机器人可以索引您的网站的频率,以及它们在一次抓取中可以访问的 URL 总数。 将您的抓取预算想象为您可以在服务或应用程序中花费的积分。 如果您不记得“收取”您的抓取预算,机器人会放慢速度并减少您的访问次数。
在 SEO 中,“收费”是指为获取反向链接或提高网站的整体知名度所做的工作。 因此,抓取预算是整个 Web 生态系统不可或缺的一部分。 当您在内容和反向链接方面做得很好时,您就提高了可用抓取预算的限制。
在其资源中,谷歌没有冒险明确定义抓取预算。 相反,它指出了影响 Googlebot 的彻底性和访问频率的两个基本抓取组件:
- 抓取速度限制;
- 抓取需求。
什么是抓取速度限制以及如何检查?
简单来说,抓取速度限制是 Googlebot 在抓取您的网站时可以建立的同时连接数。 由于 Google 不想损害用户体验,因此它会限制连接数以保持您的网站/服务器的流畅性能。 简而言之,您的网站越慢,您的抓取速度限制就越小。
重要提示:抓取限制还取决于您网站的整体 SEO 健康状况——如果您的网站触发了许多重定向、404/410 错误,或者服务器经常返回 500 状态代码,那么连接数也会下降。
您可以使用 Google Search Console 中的Crawl Stats 报告中提供的信息来分析抓取速率限制数据。
爬取需求,或网站受欢迎程度
虽然抓取速度限制要求您完善网站的技术细节,但抓取需求会奖励您网站的受欢迎程度。 粗略地说,您网站(及其上)的嗡嗡声越大,其抓取需求就越大。
在这种情况下,谷歌盘点了两个问题:
- 总体受欢迎程度——谷歌更渴望对互联网上普遍流行的 URL 进行频繁的爬网(不一定是那些来自最多 URL 的反向链接)。
- 索引数据的新鲜度——Google 力求只提供最新信息。 重要提示:创建越来越多的新内容并不意味着您的总体抓取预算限制会增加。
影响爬取预算的因素
在上一节中,我们将抓取预算定义为抓取速率限制和抓取需求的组合。 请记住,您需要同时处理这两个问题,以确保正确抓取您的网站(并因此编制索引)。
您将在下面找到在抓取预算优化期间要考虑的简单要点列表
- 服务器——主要问题是性能。 您的速度越低,Google 分配更少资源来索引您的新内容的风险就越高。
- 服务器响应代码——您网站上的 301 重定向和 404/410 错误的数量越多,您获得的索引结果就越差。 重要提示:注意重定向循环 - 每个“跳跃”都会降低您网站的爬取率限制,以便机器人下次访问。
- robots.txt 中的块——如果您的 robots.txt 指令基于直觉,您最终可能会造成索引瓶颈。 结果:您将清理索引,但以牺牲新页面的索引效率为代价(当被阻止的 URL 牢固地嵌入整个网站的结构中时)。
- 分面导航/会话标识符/URL 中的任何参数——最重要的是,请注意以下情况:带有一个参数的地址可能会被进一步参数化,而没有任何限制。 如果发生这种情况,Google 将访问无限数量的地址,将所有可用资源用于我们网站的次要部分。
- 重复的内容——复制的内容(除了自相残杀)会严重损害索引新内容的有效性。
- Thin Content – 当页面的文本与 HTML 的比率非常低时会发生这种情况。 因此,Google 可能会将页面识别为所谓的 Soft 404 并限制对其内容的索引(即使内容有意义,例如,在制造商的页面上展示单一产品且没有唯一文字内容)。
- 内部链接不良或缺乏。
抓取预算分析的有用工具
由于抓取预算没有基准(这意味着很难比较网站之间的限制),因此请配备一组旨在促进数据收集和分析的工具。
谷歌搜索控制台
多年来,GSC 成长得很好。 在抓取预算分析期间,我们应该查看两个主要报告:索引覆盖率和抓取统计信息。
GSC 中的指数覆盖率
该报告是一个海量数据源。 让我们检查有关从索引中排除的 URL 的信息。 这是了解您面临的问题规模的好方法。
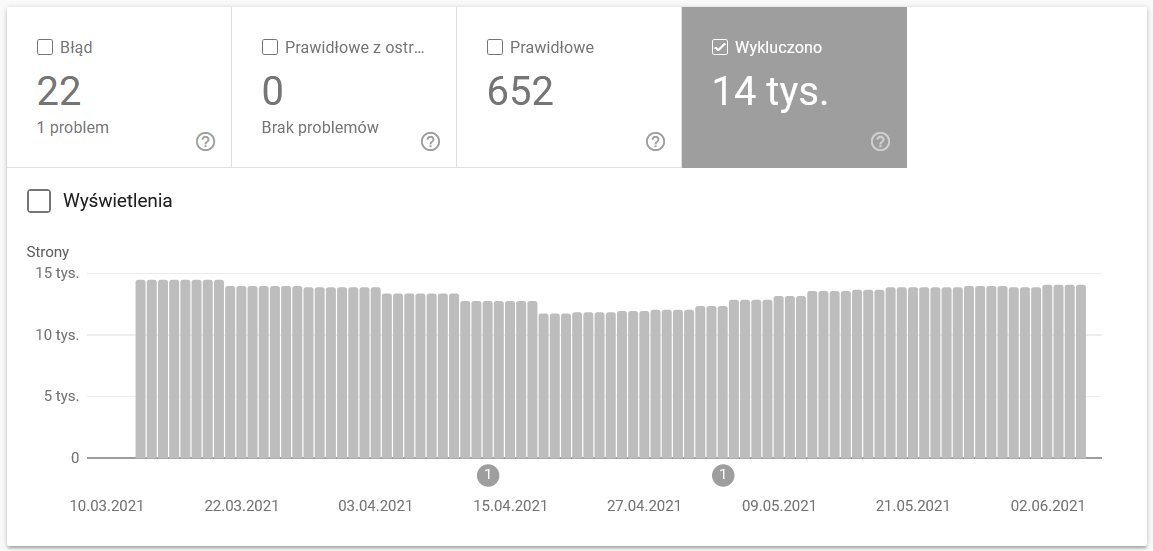
整个报告值得单独写一篇文章,所以现在,让我们关注以下信息:
- 被“noindex”标签排除——一般来说,更多的 noindex 页面意味着更少的流量。 这就引出了一个问题——将它们保留在网站上的意义何在? 如何限制对这些页面的访问?
- 已抓取 - 当前未编入索引- 如果您看到该内容,请检查内容在 Googlebot 眼中是否正确呈现。 请记住,每个具有该状态的 URL 都会浪费您的抓取预算,因为它不会产生自然流量。
- 已发现(目前未编入索引)是值得将其放在优先级列表顶部的更令人担忧的问题之一。
- 在没有用户选择的规范的情况下重复 - 所有重复页面都非常危险,因为它们不仅会损害您的抓取预算,还会增加同类相食的风险。
- 重复,谷歌选择了与用户不同的规范——理论上,没有必要担心。 毕竟,谷歌应该足够聪明,可以代替我们做出明智的决定。 好吧,实际上,谷歌非常随机地选择它的规范——通常会用指向主页的规范切断有价值的页面。
- 软 404 - 所有“软”错误都非常危险,因为它们可能导致从索引中删除关键页面。
- 重复的、提交的 URL 未被选为规范- 类似于缺少用户选择的规范的状态报告。
抓取统计
该报告并不完美,就建议而言,我强烈建议也使用良好的旧服务器日志,这可以更深入地了解数据(以及更多建模选项)。
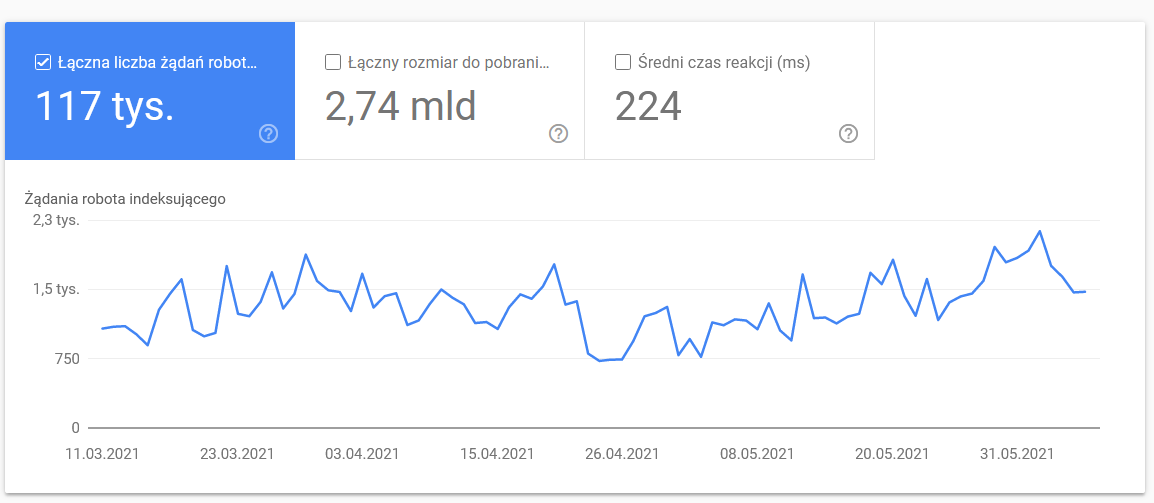
正如我已经说过的,您将很难为上述数字寻找基准。 但是,最好仔细看看:
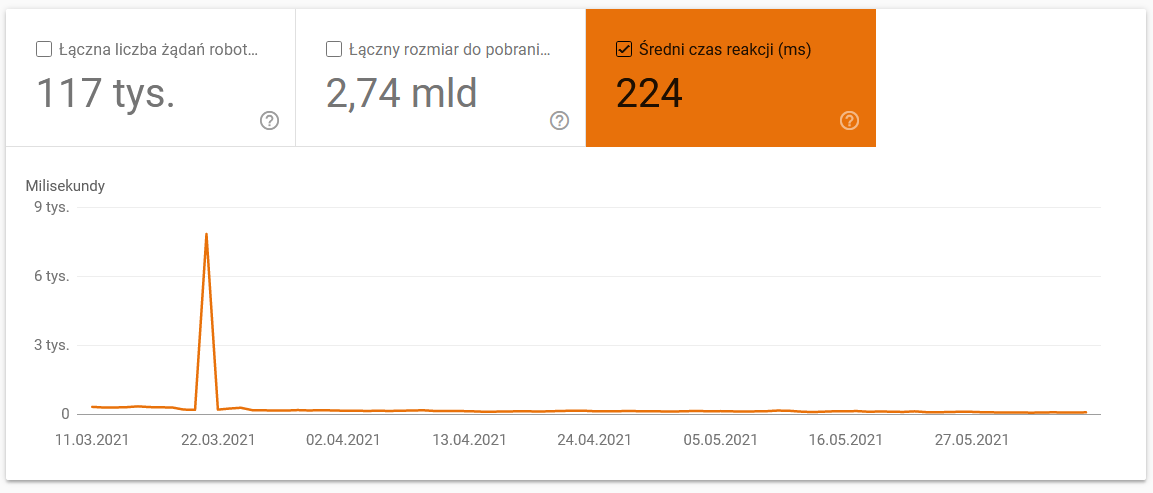
- 平均下载时间。 下面的屏幕截图显示,平均响应时间受到了巨大的打击,这是由于与服务器相关的问题:
- 抓取响应。 总体而言,查看报告以了解您的网站是否存在问题。 密切注意非典型服务器状态代码,例如下面的 304。 这些 URL 没有任何功能用途,但 Google 会浪费资源来抓取其内容。

- 爬行目的。 一般来说,这些数据很大程度上取决于网站上新内容的数量。 谷歌和用户收集的信息之间的差异可能非常有趣:
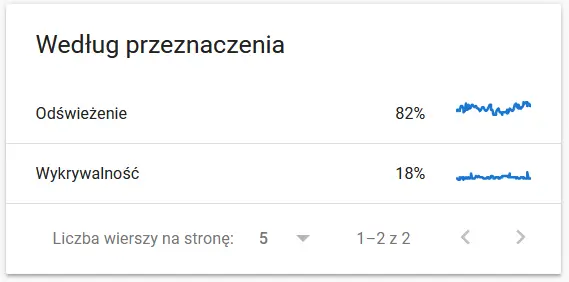
Google 眼中重新抓取的 URL 的内容:
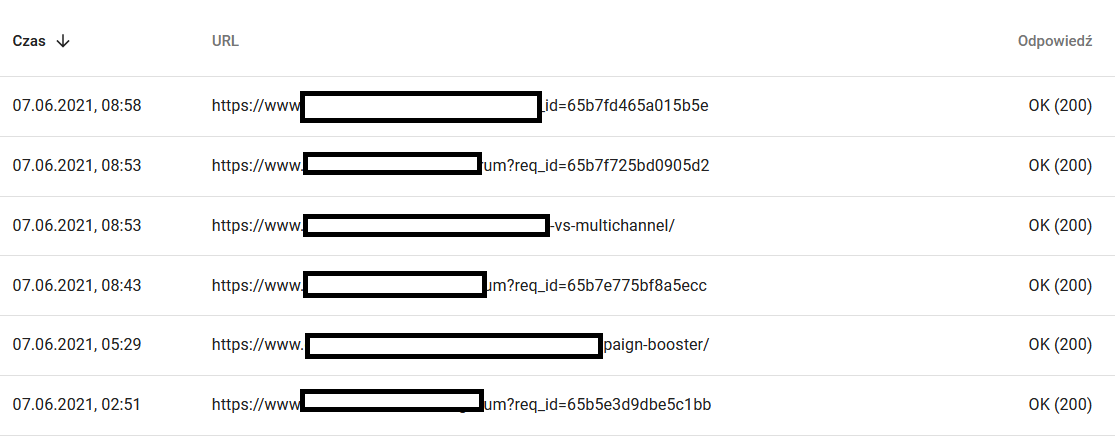
同时,这是用户在浏览器中看到的内容:
绝对是思考和分析的原因:)
- 谷歌机器人类型。 在这里,您可以让机器人在银盘上访问您的网站,以及它们解析您的内容的动机。 下面的屏幕截图显示 22% 的请求涉及页面资源加载。
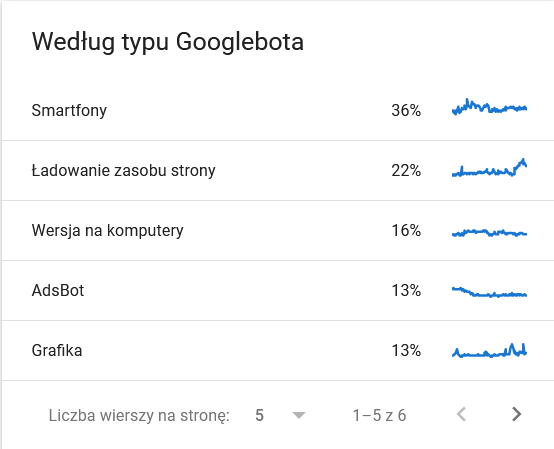
在时间框架的最后几天,总数激增:
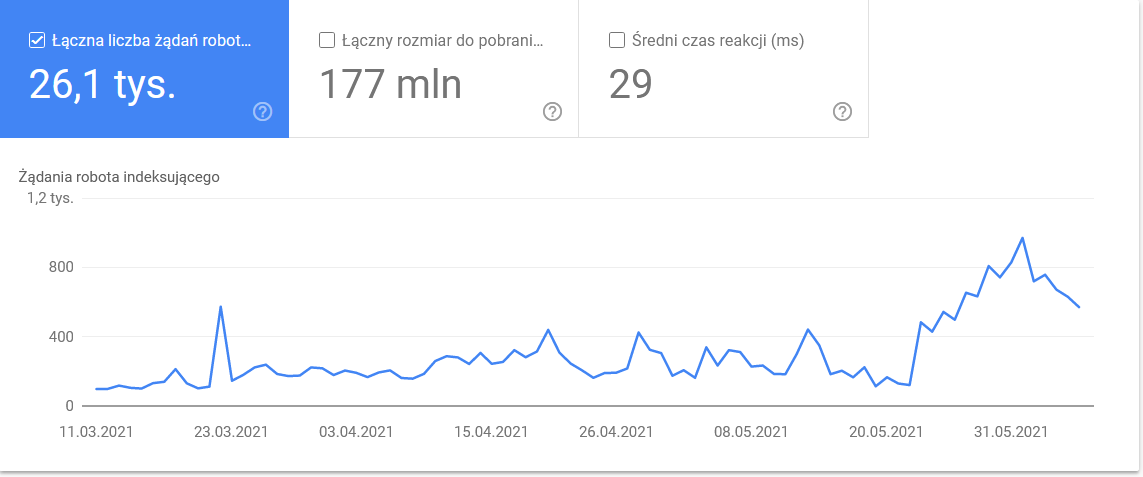
查看详细信息会发现需要密切注意的 URL:
外部爬虫(来自 Screaming Frog SEO Spider 的示例)
抓取工具是分析网站抓取预算的最重要工具之一。 他们的主要目的是模仿网站上爬行机器人的动作。 模拟一目了然地向您展示一切是否顺利。
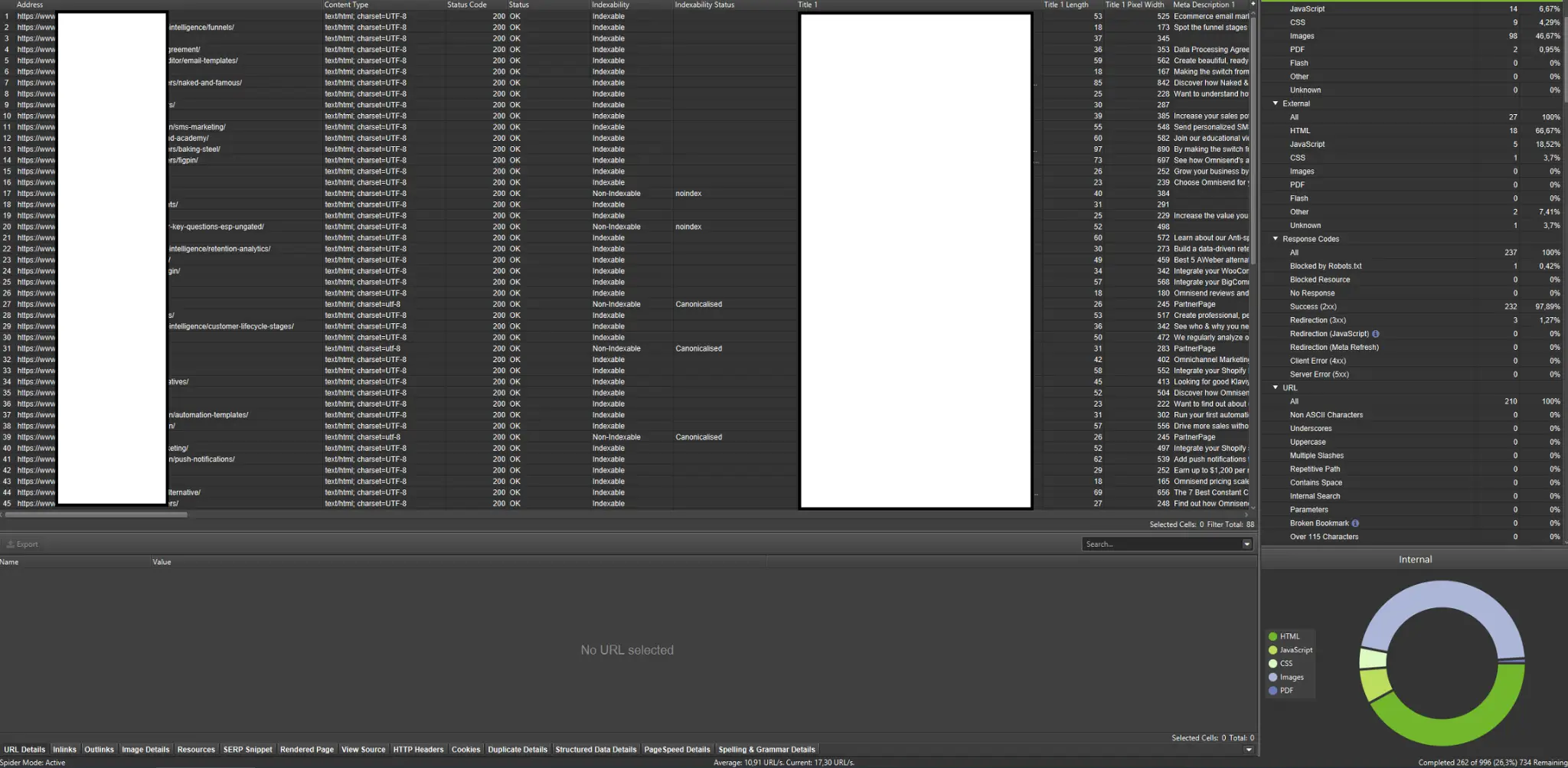
如果您是视觉学习者,您应该知道市场上可用的大多数解决方案都提供数据可视化。
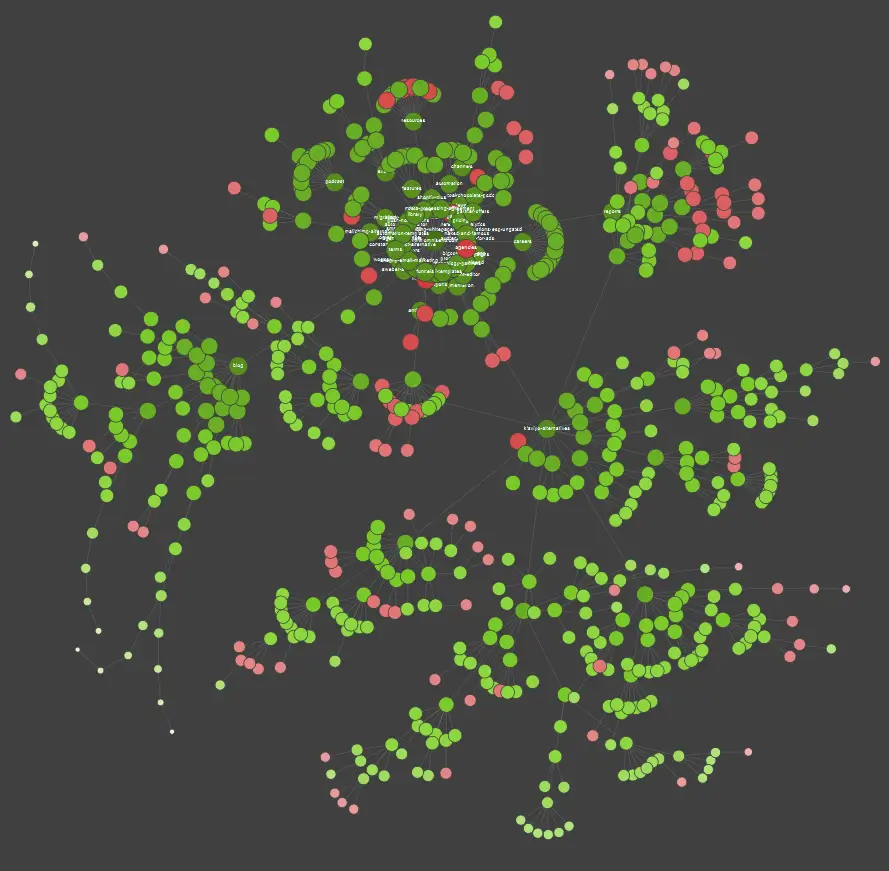
在上面的示例中,红点代表非索引页面。 花点时间考虑一下它们的有用性和对网站运营的影响。 如果服务器日志显示这些页面浪费了 Google 的大量时间而没有增加任何价值 - 是时候认真重新考虑将它们保留在网站上的意义了。

重要提示:如果我们想尽可能准确地重现 Googlebot 的行为,则必须进行正确的设置。 在这里,您可以从我的计算机中看到示例设置:
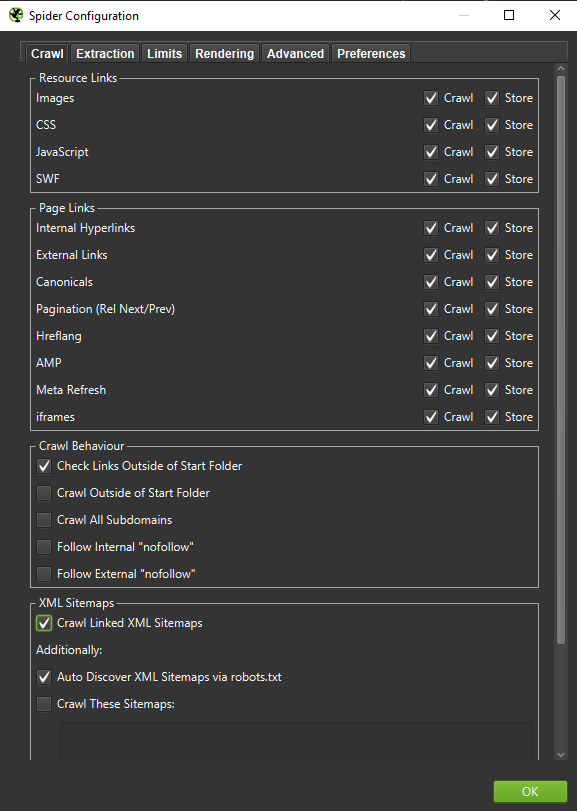
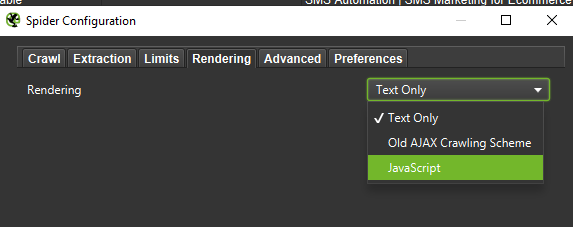
在进行深入分析时,最好测试两种模式——纯文本,还有 JavaScript——来比较差异(如果有的话)。
最后,在两个不同的用户代理上测试上面介绍的设置永远不会有坏处:
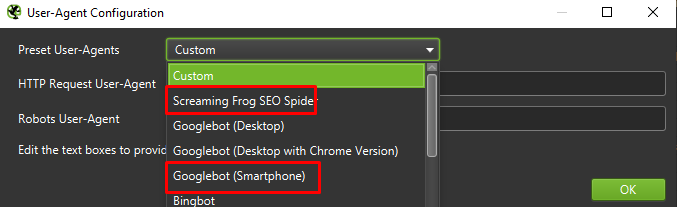
在大多数情况下,您只需关注移动代理抓取/呈现的结果。
重要提示:我还建议利用 Screaming Frog 提供的机会,向您的爬虫提供来自 GA 和 Google Search Console 的数据。 该集成是一种快速识别抓取预算浪费的方法,例如大量没有接收流量的潜在冗余 URL。
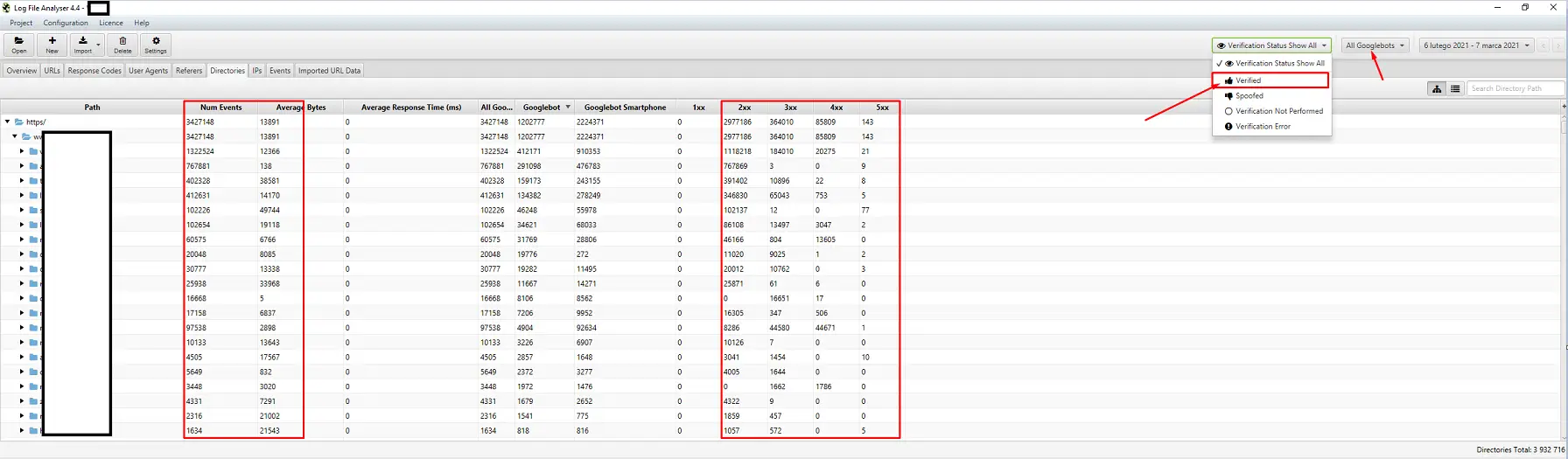
日志分析工具(Screaming Frog Logfile 等)
服务器日志分析器的选择是个人喜好问题。 我的首选工具是 Screaming Frog Log File Analyzer。 它可能不是最有效的解决方案(加载大量日志 = 挂起应用程序),但我喜欢这个界面。 重要的部分是命令系统仅显示经过验证的 Googlebot。
可见性跟踪工具
一个有用的帮助,因为它们可以让您识别您的首页。 如果一个页面在 Google 中的许多关键字排名很高(= 获得大量流量),它可能有更大的抓取需求(在日志中检查 - Google 真的为这个特定页面产生更多点击吗?)。
出于我们的目的,我们需要 Senuto 中的一般报告——路径和 URL——以供将来继续查看。 这两个报告都在可见性分析的“部分”选项卡中可用。 看一看:
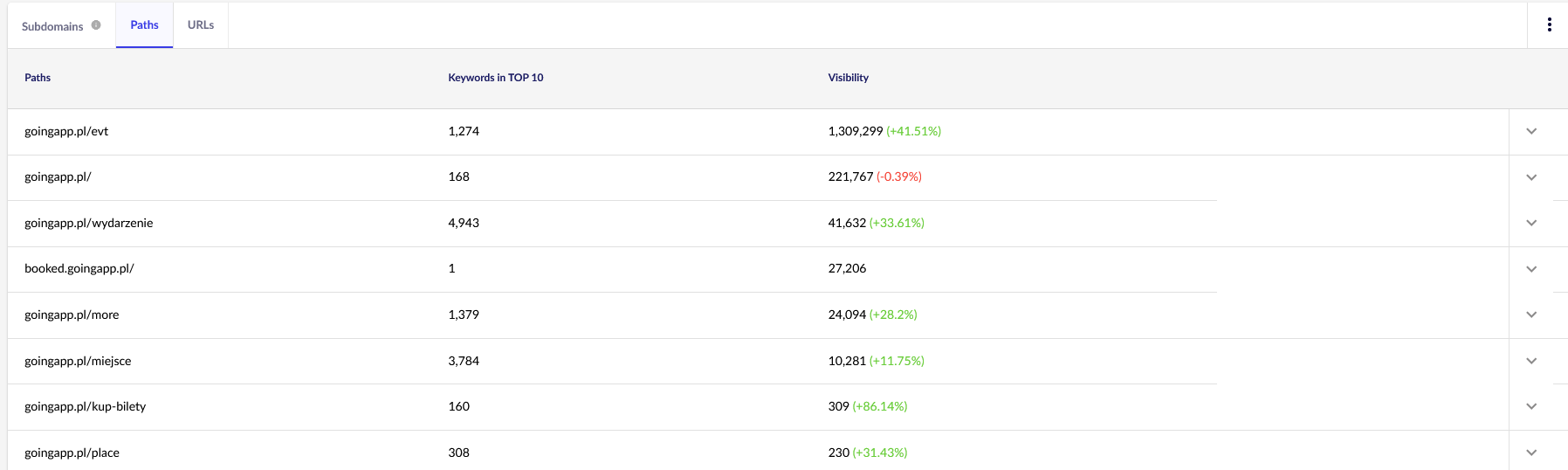
我们的主要兴趣点是第二份报告。 让我们对其进行排序以查看我们的关键字可见性(我们的网站在 TOP 10 中排名的关键字列表和总数)。 结果将帮助我们确定刺激(和有效分配)我们的抓取预算的主轴。
反向链接分析工具(Ahrefs,Majestic)
如果您的某个页面具有大量入站链接,请将其用作您的抓取预算优化策略的支柱。 热门页面可以扮演中心的角色,进一步传递信息。 此外,具有大量有价值链接的流行页面更有可能吸引频繁的抓取。
在 Ahrefs 中,我们需要 Pages 报告,确切地说,它的部分标题为:“Best by links”:
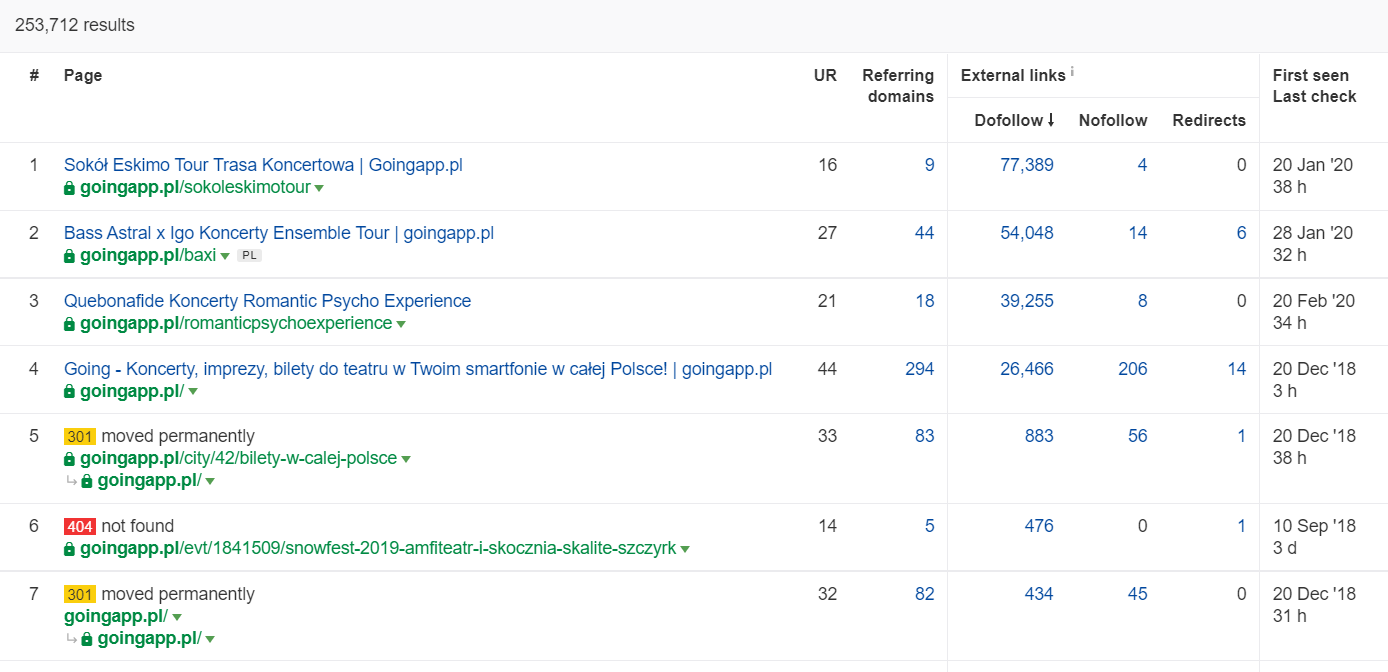
上面的例子表明,一些与音乐会相关的 LP 继续为反向链接生成可靠的统计数据。 即使由于大流行而取消了所有音乐会,使用历史上强大的页面来激起爬行机器人的好奇心并将汁液传播到您网站的更深角落仍然是值得的。
爬行预算问题的明显迹象是什么?
意识到您正在处理有问题(过低)的抓取预算并非易事。 为什么? 主要是因为 SEO 是一个极其复杂的企业。 低排名或索引问题也可能是平庸的链接配置文件或网站上缺乏正确内容的结果。
通常,抓取预算诊断涉及检查:
- 假设您不通过 Google Search Console 请求索引,从发布到索引新页面(博客文章/产品)需要多长时间?
- Google 会将无效 URL 保留在其索引中多长时间? 重要提示:重定向地址是一个例外——谷歌会故意存储它们。
- 您是否有页面进入索引后才退出?
- Google 在无法产生价值(流量)的页面上花费了多少时间? 去日志分析一探究竟。
如何分析和优化爬取预算?
进行爬网预算优化的决定主要取决于您网站的大小。 谷歌建议,一般来说,少于 1000 页的网站不应该为充分利用其可用的抓取限制而苦恼。 在我的书中,如果您的网站包含 300 多个页面并且您的内容是动态变化的(例如,您不断添加新页面/博客文章),您应该开始争取更高效和有效的抓取。
为什么? 这是一个 SEO 卫生问题。 早期实施良好的优化习惯和良好的爬虫预算管理,以后您将减少整改和重新设计。
抓取预算优化。 标准程序
一般来说,人员预算分析和优化工作包括三个阶段:
- 数据收集,这是从网站管理员和外部工具收集我们所知道的关于网站的所有信息的过程。
- 可见性分析和低挂果实的识别。 什么像发条一样运转? 有什么更好的? 哪些领域的增长潜力最大?
- 爬网预算的建议。
抓取预算审计的数据收集
1. 使用其中一种市售工具执行的完整网站爬网。 目标是至少完成两次抓取:第一次模拟 Googlebot,而另一个抓取网站作为默认用户代理(浏览器的用户代理会这样做)。 在这个阶段,您只对下载 100% 的内容感兴趣。 如果您注意到爬虫陷入了循环(当爬了一天之后,我们的硬盘上仍然只有 10% 的网站)——请告知存在问题,您可以停止爬虫。 对于大型网站,用于分析的合理数量的 URL 大约是 250-30 万页。
a) 我们要查找的主要是内部 301 重定向、404 错误,以及您的文本可能被归类为精简内容的情况。 Screaming Frog 可以选择检测近乎重复的内容:
2.服务器日志。 理想的时间范围应该是上个月,但是,对于大型网站,最后两周可能就足够了。 在最好的情况下,我们应该可以访问历史服务器日志来比较 Googlebot 在一切顺利时的动作。
3. 从 Google Search Console 导出数据。 结合上面的第 1 点和第 2 点,Index Coverage 和 Crawl Stats 的数据应该可以让您对您网站上的所有事件有一个相当全面的描述。
4.有机流量数据。 由 Google Search Console、Google Analytics 以及 Senuto 和 Ahrefs 确定的热门页面。 我们希望通过高可见度统计数据、流量或反向链接计数来识别所有在人群中脱颖而出的页面。 这些页面应该成为您在抓取预算方面工作的支柱。 我们将使用它们来改进对最重要页面的抓取。
5. 人工索引审核。 在某些情况下,SEO 专家最好的朋友就是一个简单的解决方案。 在这种情况下:对直接从索引中获取的数据进行审查! 使用inurl: + site:运算符的组合检查您的网站是一个很好的选择。最后,我们需要合并所有收集到的数据。 通常,我们将使用具有允许外部数据导入(GSC 数据、服务器日志和有机流量数据)功能的外部爬虫。
可见性分析和低垂的果实
该过程需要单独的文章,但我们今天的目标是鸟瞰我们的网站目标和所取得的进展。 我们对所有不寻常的事情都感兴趣:突然的流量下降(无法用季节性趋势来解释)以及有机可见度的同时变化。 我们正在检查哪些页面组是最强的,因为它们将成为我们推动 Googlebot 深入我们网站的 HUBS。
在完美的世界中,这样的检查应该涵盖我们网站自推出以来的整个历史。 但是,随着数据量每个月都在不断增长,让我们专注于分析过去 12 个月期间的可见性和自然流量。
抓取预算——我们的建议
上面列出的活动将根据优化网站的大小而有所不同。 但是,它们是我在执行爬网预算分析时始终考虑的最重要元素。 最重要的目标是消除您网站上的瓶颈。 换句话说,保证 Googlebots(或其他索引代理)的最大可抓取性。
1. 让我们从基础开始——消除各种 404/410 错误,分析内部重定向并从内部链接中删除它们。 我们应该以最后一次爬行来结束我们的工作。 这一次,所有链接都应返回 200 响应代码,没有内部重定向或 404 错误。
- 在这个阶段,最好纠正在反向链接报告中检测到的所有重定向链。
2. 抓取后,确保我们的网站结构没有明显的重复。
- 还要检查潜在的蚕食——除了将同一关键字定位到多个页面所产生的问题(简而言之,您不再控制 Google 将显示哪个页面),蚕食会对您的整个抓取预算产生负面影响。
- 将已识别的重复项合并到一个 URL 中(通常是排名较高的 URL)。
3. 检查有多少个 URL 有 noindex 标签。 众所周知,谷歌仍然可以浏览这些页面。 他们只是没有出现在搜索结果中。 我们正在努力将我们网站结构中的noindex标签的份额降到最低。
- 举个例子——博客用标签组织它的结构; 作者声称该解决方案是由用户方便决定的。 每篇文章都标有 3-5 个标签,分配不一致且未编入索引。 日志分析显示,它是网站上被爬取次数第三多的结构。
4. 查看 robots.txt 。 请记住,实施 robots.txt 并不意味着 Google 不会在索引中显示地址。
- 检查哪些被阻止的地址结构仍在被爬取。 也许切断它们会导致瓶颈?
- 删除过时/不必要的指令。
5. 分析您网站上非规范 URL 的数量。 Google 不再将rel=”canonical”视为硬性指令。 在许多情况下,搜索引擎完全忽略了该属性(对索引中的参数进行排序——仍然是一场噩梦)。
6.分析过滤器及其底层机制。 过滤listing是爬虫预算优化最头疼的问题。 电子商务企业主坚持实施适用于任何组合的过滤器(例如,按颜色 + 材料 + 尺寸 + 可用性过滤……无数次)。 该解决方案不是最佳的,应限制在最低限度。
7. 网站上的信息架构——一种考虑业务目标、流量潜力和当前链接配置文件的架构。 让我们假设对我们的业务目标至关重要的内容的链接应该在站点范围内(在所有页面上)或主页上可见。 当然,我们在这里进行了简化,但是主页和顶部菜单/站点范围的链接是从内部链接中建立价值的最有力的指标。 同时,我们正在努力实现最佳的域传播:我们的目标是我们可以从任何页面开始抓取并且仍然达到相同数量的页面(每个 URL 应该有一个最少的传入链接) .
- 努力建立强大的信息架构是爬网预算优化的关键要素之一。 它允许我们从一个位置释放一些机器人资源并将它们重定向到另一个位置。 这也是最大的挑战之一,因为它需要业务利益相关者的合作——这通常会导致巨大的战斗和批评,从而破坏了 SEO 建议。
8.内容渲染。 对于旨在将其内部链接基于捕获用户行为的推荐系统的网站而言至关重要。 最重要的是,这些工具中的大多数都依赖于 cookie 文件。 Google 不存储 Cookie,因此不会获得自定义结果。 结果:谷歌总是看到相同的内容或根本没有内容。
- 阻止 Googlebot 访问关键的 JS/CSS 内容是一个常见的错误。 这一举措可能会导致页面索引问题(并浪费 Google 的时间来呈现不可用的内容)。
9. 网站性能 – Core Web Vitals 。 虽然我对 CWV 对网站排名的影响持怀疑态度(出于多种原因,包括商用设备的多样性和互联网连接速度的不同),但它是最值得与编码人员讨论的参数之一。
10. Sitemap.xml - 检查它是否有效并包含所有关键元素(只有返回 200 状态代码的规范 URL)。
- 我对优化 sitemap.xml 的第一个建议是按类型或(如果可能的话)类别来划分您的页面。 该部门将让您完全控制 Google 的移动和内容索引。