
了解 Google NLP 算法以獲得更好的內容 SEO
已發表: 2022-06-04
自然語言處理 (NLP) 是人工智能 (AI) 和搜索引擎算法中最複雜和最具創新性的進步之一。 而且,毫不奇怪,谷歌已經成為 NLP 領域的領導者。 隨著 2021 年 SMITH 算法和之前的自然語言算法 BERT 的加入,谷歌開發了能夠熟練理解人類語言的 AI。 而且這項技術有能力用於人工智能生成的內容創建。
Google 的 NLP 算法以非凡的準確性改變了 AI 遊戲。 那麼,這對 SEO 意味著什麼? 本文將深入探討 Google NLP 技術的所有細節,以及如何使用它們在搜索引擎結果中獲得更好的排名。
什麼是自然語言處理?

自然語言處理(NLP)是計算機科學和人工智能的一個領域,涉及研究如何使計算機理解人類語言。 與以前的 AI 形式不同,NLP 使用深度學習。
NLP 被認為是人工智能的重要組成部分,因為它使計算機能夠以一種感覺自然的方式與人類交互。
雖然 NLP 聽起來像是它的目的是改善谷歌的搜索結果並使作家破產,但這項技術在 SEO 之外還以多種方式使用。
以下是最常見的:
1. 情緒分析: NLP 衡量人們的情緒水平以確定諸如客戶滿意度之類的事情。
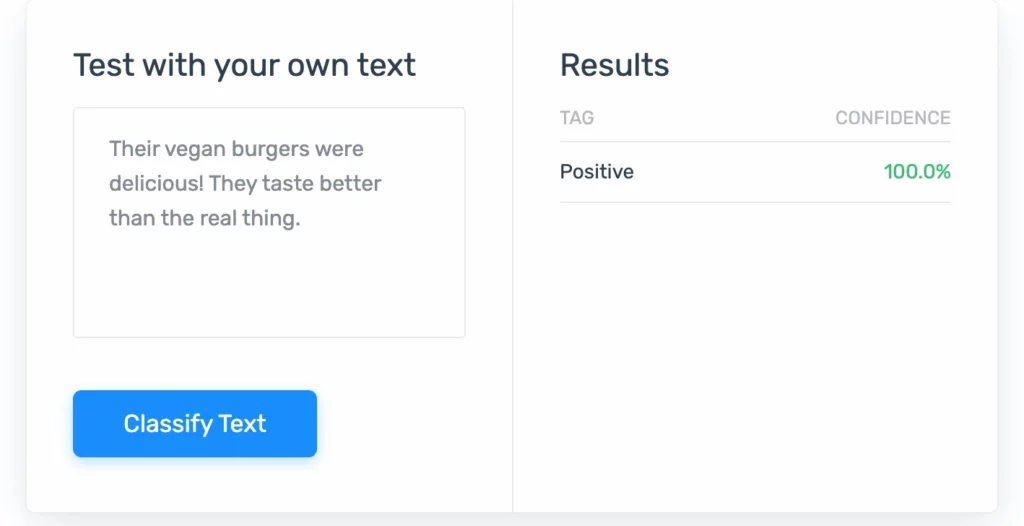
2. 聊天機器人:這些是在幫助頁面或一般網站上彈出的聊天屏幕。 他們有減少客戶支持中心工作量的訣竅。
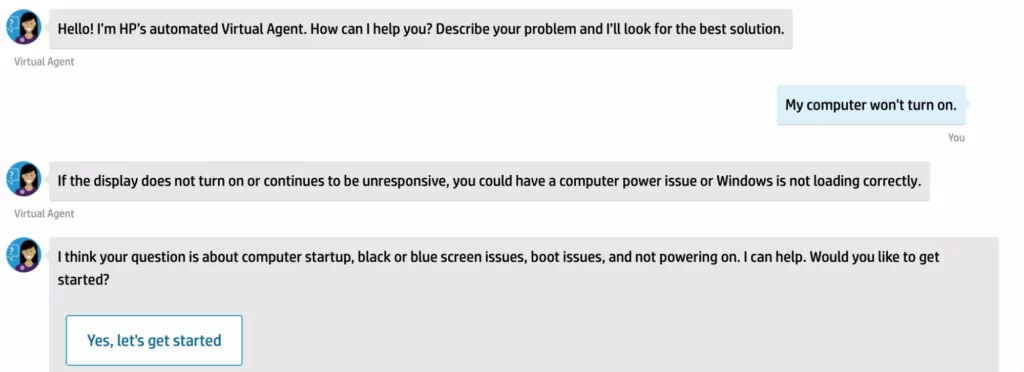

4. 語音識別:該 NLP 獲取音頻並將其轉換為命令等。

文本分類、提取和摘要:這些形式的 NLP 可以分析文本,然後將其重新格式化,以便於人類使用、分析和理解。 當涉及醫療編碼和發現計費錯誤等任務時,文本提取非常有用。
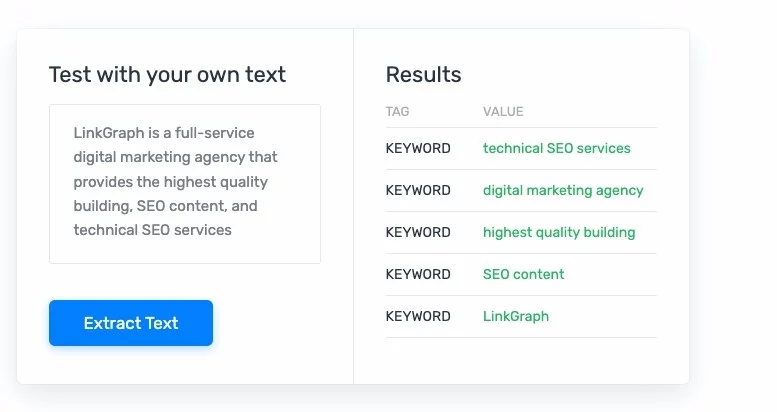
什麼是深度學習?

深度學習是機器學習的一個類別,它以人腦中的神經網絡為模型。 這種形式的機器學習通常被認為比典型的 AI 學習模型更複雜。
因為它們反映了人類的大腦,它們也可以反映人類的行為——並且學到很多東西! 深度學習算法通常使用兩部分系統。 一個系統進行預測,而另一個系統改進結果。
深度學習已經在家用設備、公共環境和工作場所使用了一段時間。 最常見的應用包括:
- 自動駕駛汽車
- 語音遙控器
- 信用卡欺詐檢測
- 醫療設備
- 基於衛星的國防
NLP如何影響SEO?

谷歌 PageRank 的更新很少破壞自然語言處理機器人等 SEO 標準。 隨著 Google 的 SMITH 的推出,我們看到 SEO 專家爭先恐後地了解算法的工作原理以及如何生成符合算法標準的內容。 但是,與大多數算法更新一樣,時間通常會揭示如何滿足和超越內容標準,以確保您的內容最有可能進入 SERP。
從本質上講,NLP可以幫助 Google 根據搜索者的意圖和對網站內容的更清晰理解,為他們提供更好的搜索結果。 這意味著只有那些提供最佳內容的網站才能在 SERP 中保持排名。 此外,不提供搜索者意圖的雜項內容將被隱藏在更深層次的 SERP 中或根本不顯示。
什麼是谷歌 BERT?

BERT(Bidirectional Encoder Representations from Transformers)算法於 2019 年推出,它掀起了自 PageRank 以來最大的變化。 該算法是一種 NLP,可用於理解文本以提供出色的搜索結果。
更具體地說, BERT 是一種神經網絡,旨在更好地理解句子中單詞的上下文。 該算法能夠通過使用稱為預訓練的技術來學習句子中單詞之間的關係。
BERT 算法的目標是提高自然語言處理任務的準確性,例如機器翻譯和問答。
Google BERT 算法是如何工作的?
BERT 算法能夠通過使用一種稱為遷移學習的技術來實現其目標。 遷移學習是一種技術,用於通過使用已經在大型數據集上訓練的預訓練網絡來提高神經網絡的準確性。
與 Google 的許多更新不同,BERT 的內部工作是開源的。 BERT 算法基於谷歌 2018 年發表的一篇論文。這個開源解釋包括 BERT 使用雙向上下文模型來更好地理解單個單詞或短語的含義。 結果是微調的內容分類。
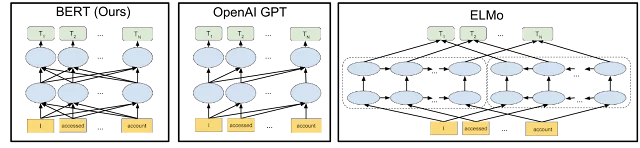
例如:
如果您正在尋找歡樂時光的酒吧而不是臥推設備的酒吧,Google 會根據單詞在頁面上下文中的使用方式向您顯示正確的酒吧類型。
還有什麼讓 BERT 與眾不同?
BERT 使用雲張量處理單元 (TPU)作為其預訓練系統,它加速了 NLP 從現有文本樣本中學習的能力。 預訓練是一種用於在處理數據之前在大型數據集上訓練神經網絡的技術。 然後使用預訓練的網絡來處理與用於訓練網絡的數據相似的數據。 通過使用雲 TPU,BERT 能夠以超快的速度處理數據。 谷歌云也能夠進行測試。
經過數百萬次的訓練,BERT 算法能夠達到比以前的自然語言處理算法更高的準確率,因為它能夠更好地理解句子中單詞的上下文。
BERT 需要多少文本樣本? BERT 使用了數百萬甚至數十億的樣本來完全掌握自然語言(不僅僅是英語)。
Google 的 Bert 更新如何影響網站?

BERT 更新對網站的影響是雙重的。 首先,更新提高了谷歌搜索結果的準確性。 這意味著在 Google 搜索結果中排名較高的網站的點擊率 (CTR) 較高。
其次,BERT 更新增加了網站內容的重要性。 這意味著具有高質量、相關內容的網站更有可能在 Google 的搜索結果中排名更高。
Google Bert 的局限性是什麼?

BERT 是一個強大的工具,但它的功能存在一些限制。 雖然這個 NLP 模型的簡潔性很容易讓人忘乎所以,但重要的是要記住,BERT 模型並不具備所有人類認知過程的能力。 這些可能是其內容理解能力的限制。
BERT 是一種純文本算法
首先,BERT 僅對涉及文本的自然語言處理任務有效。 它不能用於涉及圖像或其他形式數據的任務。 但是,請記住, BERT 可以讀取您的替代文本,這可以幫助您出現在 Google 圖片搜索中。
BERT 不了解“全貌”
其次,BERT 對於需要極高理解程度的任務無效。 本質上,BERT 擅長句子中的單詞,但不能理解整篇文章。
例如,BERT 可以理解以下句子中的“蝙蝠”指的是哺乳動物,而不是木製棒球棒:蝙蝠吞噬了蚊子。 但它對於需要理解複雜句子或段落的任務無效。
什麼是 Google SMITH 算法?

Google SMITH(或Siamese Multi-depth Transformer-based Hierarchical)算法是由 Google 工程師設計的排名算法。 該算法著眼於自然語言,學習與短語相關的意義模式以及它們之間的距離,並創建一個信息層次結構,使頁面能夠更準確地被索引。
這允許 SMITH 更有效地執行內容分類。
SMITH 的另一個有趣特性是它可以用作文本預測器。 還有其他公司在 NLP 方面掀起了波瀾(想想去年Open AI 臭名昭著的GPT-3測試版)。 其中一些技術可以幫助其他人建立自己的搜索引擎。
Google 的 SMITH 更新如何影響網站?
Google 的 SMITH 更新對網站產生了重大影響。 該更新旨在提高搜索結果的準確性,它通過懲罰使用操縱技術影響其排名的網站來做到這一點。 SMITH 旨在針對廣泛的操縱技術,包括垃圾郵件鏈接、黑帽 SEO 和人工智能,提高了質量內容和有機鏈接建設的標準。
SMITH 針對的一些最常見的操縱技術包括
- 關鍵字填充
- 鏈接購買
- 過度使用錨文本。
被發現使用這些技術的網站會受到谷歌的懲罰,導致其搜索排名下降。
Google 的 SMITH 更新和 Google BERT 有什麼區別?

BERT 模型和 SMITH 模型都為 Google 的網絡爬蟲提供了更好的語言理解和頁面索引。 我們知道 Google 已經喜歡長內容,但是當 SMITH 上線時,Google 可以更有效地理解更長的內容。 SMITH 將改進新聞推薦、相關文章推薦和文檔聚類等領域。
如何針對 Google NLP 算法調整您的 SEO 策略
雖然 Google 聲稱您無法針對 BERT 或 SMITH 進行優化,但了解如何針對 NLP 進行優化會影響您網站在 SERP 中的性能。 但是,知道 BERT 專注於提供用戶意圖意味著您應該了解要優化的任何搜索查詢的意圖。
谷歌對於何時推出他們的算法通常有點謹慎,而且他們對 SMITH 何時全面推出仍然保密。 但最好假設他們開始針對變化進行優化。
SMITH 可能只是Google保持其在 NLP 和機器學習技術領域的主導地位的長期目標的眾多迭代之一。 隨著谷歌提高對完整文檔的理解,良好的信息架構將變得更加重要。
您如何針對 Google 的 NLP 算法優化您的內容?

- 確保您的內容格式正確且易於閱讀。 保持標題最佳實踐和其他可讀性最佳實踐。 這些包括:
- 將句子控制在 20 個單詞以下
- 對大於 2 的所列項目使用項目符號列表
- 使用正確的標題層次結構
- 避免向讀者展示難以理解的文本塊
- 使用清晰、簡潔、易於理解的語言。 不要過度複雜你的句子結構。 通過限制你的句子長度,你可能還會簡化你的想法。
- 避免使用可能會混淆 Google 算法的複雜或難懂的詞。 拋棄同義詞庫,讓你的句子直截了當。 請記住,到達某事的最短路徑通常是最好的。
- 使用與您的主題相關的關鍵字和焦點術語。 語義相關的焦點術語可以幫助谷歌自然語言處理器更好地理解你的整個頁面。
- 確保您的內容是最新的。 請記住,這些 NLP 算法的動機是改善搜索結果,同時清除垃圾、過時的內容。
- 編寫人們想要閱讀的有趣且引人入勝的內容。 為搜索者提供滿足其需求的最佳內容永遠不會出錯。 請記住搜索意圖和主題深度。
- 您的客戶評論很重要。 谷歌的 NLP 可能會執行實體情感分析,所以不要忽視差評。 如果您收到負面評論(無論是英語還是火星語),您可以打賭 Google 的實體情緒分析會將您推低 SERP。
- 為搜索者的問題提供明確的答案。 如果您想在精選片段中結束,只有在您使用實體分析進行文本提取時,Google 的 NLP 才會讓您到達那裡。 這意味著谷歌有能力細化特定信息以顯示給搜索者。
谷歌 NLP 的未來
谷歌自然語言 API 和雲 TPU 現在可供所有人使用。 因此,如果您可以使用深度學習機器學習平台來執行 NLP 任務,您可以使用 Google 的自然語言 API。 如果您願意,您甚至可以參與培訓 Google 雲 NLP !
針對 Google Natural Language API 進行優化並獲取結果
有一點很清楚:自然語言 API 將繼續存在。 從 BERT 模型和 SMITH 模型的演進可以看出,谷歌搜索算法只會越來越好地理解你的內容。
讓您的口號保持不變:專注於內容,專注於質量。 雖然 SEO 將不斷學習和試驗以找出最適合 Google 的 NLP 算法的方法,但始終堅持 SEO 的最佳實踐。 請記住,您所寫的內容會影響您的排名,但您的客戶和訪問者所寫的內容也會受到情緒分析的影響。 了解有關 BERT 算法的更多信息。
SearchAtlas 的 AI 內容生成工具基於 Google 的自然語言 API 構建,因此您可以輕鬆生成最高質量的內容。