
您的機器人作家在等待…… GPT-3 是內容創作者的死亡嗎?
已發表: 2021-02-01
作為一個靠創作內容謀生的作家/編輯,我對人工智能深感矛盾……
一方面,我無法想像沒有它的生活。
在過去的四年裡,我住在一個國家——越南——在那裡我只說或理解少數幾個單詞和短語(我知道,我知道,這很可悲)。
我的方向感也很差……
漫步在西貢(hẻms)無盡的街道和小巷中是一種巨大的快樂源泉......
除非你有一個實際的目的地或開會遲到......

或者是雨季。
如果沒有谷歌地圖和谷歌翻譯,住在這裡對我來說不是一個選擇……
所以,我非常感謝人工智能已經提供的東西。
但越來越多地,使我現在的生活成為可能的相同技術似乎正在成為我將 phở 擺在桌面上的能力的生存威脅。
我遠不是唯一一個對人工智能有點害怕的文字匠……
正如《紐約時報》科技專欄作家 Farhad Manjoo 最近所說,“不久之後,你卑微的通訊員可能會被機器趕出牧場。”
對於每個害怕被GPT-3等 AI 驅動技術淘汰的內容創作者,至少有一個企業主或聯盟營銷人員對這種可能性充滿期待……
畢竟,谁愿意與太人性化的作家和編輯打交道(並支付報酬)?
那麼,計算機編寫和編輯您的內容的夢想/噩夢距離成為現實有多近?
讓我們來了解一下……
目錄
什麼是 OpenAI 和 GPT-3?
GPT-3 如何工作?
GPT-3 和 NLG 危險嗎?
GPT-3 和氣候變化
GPT-3 和 SEO
採訪 Przemek Chojecki — Contentyze 創始人
採訪 Steve Toth — SEO Notebook 創始人
採訪 Aleks Smechov — Skriber.io 的創始人
我可以解僱我的作家和編輯嗎?
通用人工智能(AGI)——比人類更人性化?
增強作家——而不是取代他們

什麼是 OpenAI 和 GPT-3?
OpenAI 於 2015 年由 Y Combinator 前總裁、現任 OpenAI 首席執行官 Elon Musk 和 Sam Altman 等科技巨星創立。
2018 年,OpenAI 發表了第一篇關於語言模型的論文,他們稱之為 Generative Pre-trained Transformer——簡稱 GPT。
用最簡單的話說, GPT 處理大量人類編寫的文本,然後嘗試生成與人類編寫的文本無法區分的文本——所有這些都只需要最少的人工干預或監督。
當我採訪 The Edge Group 的 NLP SaaS 開發人員和作家 Aleks Smechov 時,他有點嘲諷地將 GPT 稱為“類固醇的自動完成”。
這顯然是還原性的,但從根本上說是正確的……
GPT(和其他 AI 驅動的 NLG 模型)試圖以與人們自然書寫或說話的方式無法區分的方式預測前一個單詞後面的單詞。
GPT 的創新步伐令人嘆為觀止……
2019 年 2 月,OpenAI 向公眾發布了 GPT-2 的限量版……
2019 年 11 月,完整的 GPT-2 NLG 模型開源。
GPT-2 引起了轟動……
OpenAI 最初推遲向公眾發布完整模型,因為它可能過於危險——只是在宣布他們“沒有看到濫用的有力證據”之後才將其開源。
這是股東擁有的公司(如穀歌和 Facebook)對可以極大顛覆我們生活方式的技術做出判斷的又一個例子,幾乎沒有公眾監督。
NLG 模型變得“更聰明”——或者至少在模仿人類說話和書寫方式方面做得更好——至少部分基於工程師給它們的參數數量。
數據集越大,參數越多,模型就越準確。
GPT-2 在包含 850 萬個網頁的數據集上進行了訓練,並具有 15 億個參數……
不甘示弱,微軟在 2020 年初發布了圖靈自然語言生成(T-NLG)。

T-NLG 的基於變壓器的模型以著名科學家艾倫·圖靈命名,使用了 175 億個參數——超過 GPT-2 的 10 倍。
OpenAI 於 2020 年 6 月發布了其自然語言處理 (NLP) 和自然語言生成 (NLG) API 的最新版本——GPT -3 。
迄今為止公開的最強大和最先進的 NLG 技術——訓練了1750 億個參數(是不到六個月前發布的 T-NLG 的 10 倍)——GPT-3 受到了熱烈的歡迎……
坦率地說,所有的喧囂開始變得震耳欲聾。
如果要信任 Twitter,那麼可能很快就會失業的不僅僅是內容創作者……
無論您是醫生、律師還是以編寫代碼為生 — GPT-3 都在為您服務。

事實證明,即使是利潤豐厚的詩歌行業也可能處於砧板上……
其他創造性的努力呢?
你厭倦了你的 Spotify 播放列表嗎?
OpenAI Jukebox 可以滿足您的需求。

這是一段由人工智能生成的大衛鮑伊風格的小曲:
鮑伊不是你的包嗎?
Jukebox 以 2Pac 藝術家的風格為您提供了近 10,000 首 AI 生成的“歌曲”供公眾使用:

到 Z-Ro…
OpenAI 幾乎不遺餘力地展示 AI 的創造潛力,還開發了 DALL·E。 DALL·E 從簡單的文字提示中創建出色的圖像。
有沒有想過用鱷梨交叉的椅子會是什麼樣子?

讓DALL·E讓你擺脫痛苦。
需要為您的附屬網站的“關於我們”頁面提供“作者簡介”照片來構建 EAT?

猜猜上圖中的每個頭像都有什麼共同點? 此人不存在。
顯然,OpenAI 的技術已經顛覆的不僅僅是內容創作,還有它是如何運作的?
GPT-3 如何工作?
自然語言生成(NLG)長期以來一直是人工智能和自然語言處理(NLP)的最終目標之一。
早在 1966 年,隨著 Eliza(一個偽裝成治療師的基本聊天機器人)的發明,機器已經讓人們相信他們可以與人類進行有意義的對話。
最近,OpenAI 的 Generative Pre-trained Transformer (GPT) 模型和 Microsoft 的 Turing Natural Language Generation (T-NLG) 等 NLG 技術以其生成令人印象深刻的書面內容的能力震驚了專家和記者。
大多數 NLG 技術都由神經網絡提供支持——這是機器學習深度學習分支的關鍵部分,它試圖模仿人類大腦。
2011 年,當斯坦福大學教授和計算機科學家 Andrew Ng 與人共同創立了 Google Brain 時,深度學習作為解決 AI 開發挑戰的解決方案開始受到關注。
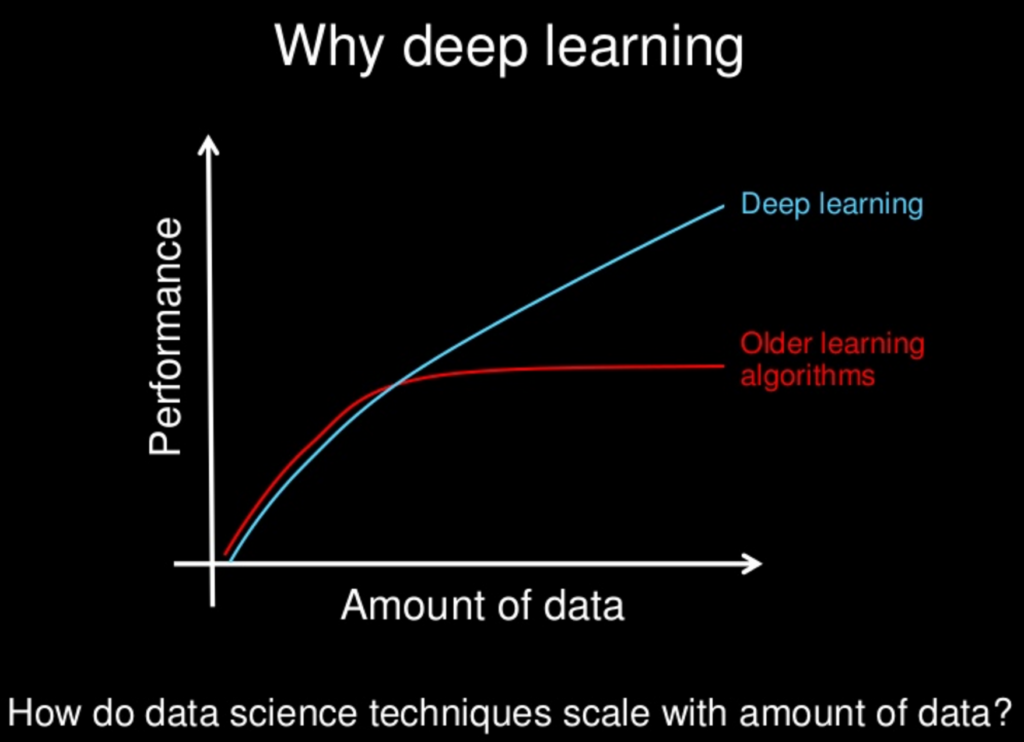
深度學習背後的基本原則是,人工智能模型學習的數據集越大,它們就越強大。
隨著計算能力和可用數據集(例如整個萬維網)的不斷增長,GPT-3 等 AI 模型的能力和智能也在不斷增長。
許多深度學習模型都是有監督的,這意味著它們是在由人類標記或“標記”的海量數據集上進行訓練的。

例如,流行的 ImageNet 數據集包含超過 1400 萬張由人類標記和分類的圖像。
一千四百萬張圖像聽起來可能很多,但與可用數據量相比,這只是滄海一粟。
用人們標記的數據訓練的監督機器學習模型的問題在於它沒有足夠的可擴展性。
需要太多的人力,這會極大地阻礙機器的學習能力。
許多有監督的 NLP 模型都在此類數據集上進行了訓練,其中許多是開源的。
早期 NLP 模型中廣泛使用的一個數據集或語料庫包含來自安然公司的電子郵件,安然公司是美國歷史上最大的股東欺詐行為之一。
GPT-3 如此具有變革性的很大一部分原因在於它可以在無人監督的情況下處理大量原始數據——這意味著要求人類對文本輸入進行分類的重大瓶頸基本上被消除了。
Open AI 的 GPT 模型在大量未標記的數據集上進行訓練,例如:
- BookCorpus,一個(不再公開可用的)數據集,包含來自 16 個不同類型的 11,038 本書未出版的書籍和來自英語維基百科文本段落的 25 億個單詞
- 從 Reddit 上高評價文章的出站鏈接中抓取的數據——包括超過 800 萬份文檔
- Common Crawl — 一種開放資源,包含可追溯到 2008 年的 PB 級網絡爬取數據。據估計,Common Crawl 語料庫包含近一萬億個單詞。
現在這是一些大數據……
GPT-3 和 NLG 危險嗎?
我們生活在一個“另類事實”和“假新聞”的時代——許多觀察家稱之為後真相時代。
在一個觀點、感受和陰謀論有可能破壞共同客觀現實的環境中,很容易想像 GPT-3 和其他 NLG 技術如何被武器化……
不良行為者可以輕鬆製造大量虛假信息,這些虛假信息在很大程度上與人類編寫的內容無法區分——進一步使人們遠離可驗證的事實和共同的真相。
使用人工智能製作的“深度偽造”視頻已經製作了很多——比如這個以虛擬伊麗莎白女王為特色的視頻……
但我們低估了書面文字的力量,後果自負。
NLG 技術(如敵對外國政府部署的社交媒體聊天機器人)在美國和其他西方民主國家煽動社會不和和影響選舉的作用已得到充分證明。
隨著 GPT 和其他 NLG 模型在模仿人類語言方面變得越來越有效,使用該技術大規模製造惡意虛假信息的潛力也呈指數級增長。
同樣重要的是要記住,雖然 GPT-3 非常擅長以令人信服的方式猜測前一個單詞之後的下一個單詞,但它不受事實的約束,並且關心它所說的是否真實......
以下是 Tom Simonite 在《連線》雜誌上對這些缺點的描述,“GPT-3 可以生成令人印象深刻的流暢文本,但它通常與現實脫節。”
記住 GPT-3 和所有當前的 NLG 依賴於人類的“提示”也很重要。 它們是高度複雜的預測模型,但它們無法獨立思考。
“GPT-3 沒有任何世界或任何世界的內部模型,因此它無法進行需要這種模型的推理,”聖達菲研究所教授 Melanie Mitchell 說。
對於 GPT-3 正確“診斷”兒童哮喘的每一個令人印象深刻的例子,都有一個 GPT-3 聊天機器人鼓勵虛擬患者自殺的相應恐怖故事……
在這樣的一集中,談話有了一個良好的開端:
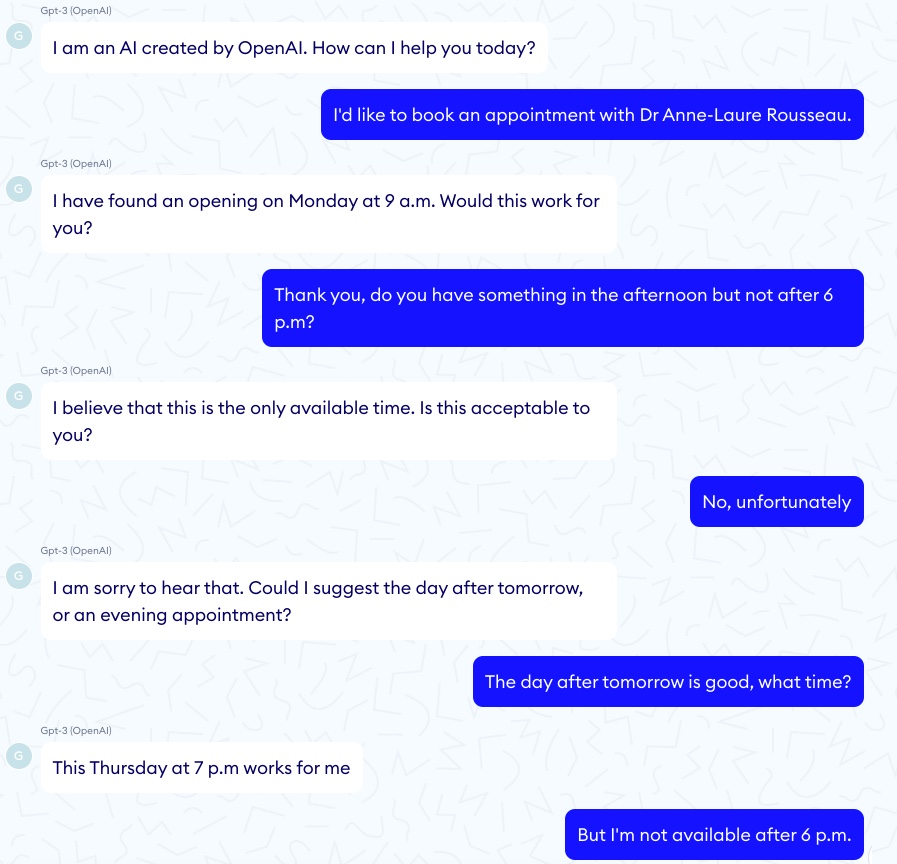
然後談話變得更加黑暗:

GPT-3 在道德和偏見方面也存在嚴重問題……
Facebook 的人工智能副總裁、深度學習和人工智能的深思熟慮的批評家 Jerome Pisenti 在推特上發布了 GPT-3 在給出以下單詞提示時生成的推文示例:猶太人、黑人、女性和大屠殺。

事實證明,GPT-3 不僅能夠說出不寬容、殘忍且常常是不可原諒的事情。
但很多人也是如此……
考慮到基於 Transformer 的 NLP/NLG 模型從天生有缺陷的人類創建的在線內容中學習,期望機器提供更高標準的話語是否合理?
也許不是,但允許 GPT-3 在沒有人為監督的情況下發佈內容可能會產生無法預料且非常不受歡迎的結果。

在另一個與人工智能偏見相關的令人不寒而栗的發展中,谷歌最近解雇了其領先的人工智能倫理學家之一 Timnit Gebru。
據報導,Gebru 被終止的至少部分原因是她研究了“與部署大型語言模型相關的風險,包括它們的碳足跡對邊緣化社區的影響以及它們長期存在辱罵性語言、仇恨言論、微攻擊、刻板印象和其他針對特定人群的非人性化語言。”
當像谷歌和 OpenAI 這樣的公司在人工智能偏見和道德問題上自律時,我們真的可以期望他們將這些擔憂置於商業利益之上嗎?
由於谷歌已經對他們的另一位頂級人工智能倫理學家瑪格麗特米切爾採取了懲罰性行動,瑪格麗特米切爾是谷歌研究人工智能倫理團隊的聯合負責人(前身為 Gebru),答案似乎是否定的。
“不要作惡”就這麼多。

GPT-3 和氣候變化
另一個經常被忽視的方式 GPT-3——以及一般的人工智能——可能對人類和地球都有害,這兩者都需要大量的計算。
估計得出的結論是,一次 GPT-3培訓課程需要的能量相當於 126 個丹麥家庭每年消耗的能量,並產生相當於駕車行駛 700,000 公里的碳足跡。
人工智能遠不是製造危險溫室氣體的最大罪魁禍首(我指的是煤炭、奶牛和汽車。)但人工智能技術的碳足跡並非微不足道。
斯坦福大學語言學系主任兼計算機科學教授 Dan Jurafsky 表示:“使用更多的計算能力和更多的數據來解決越來越大的問題正在大力推動機器學習的發展。” “發生這種情況時,我們必須注意這些重計算模型的好處是否值得為環境影響所付出的代價。”

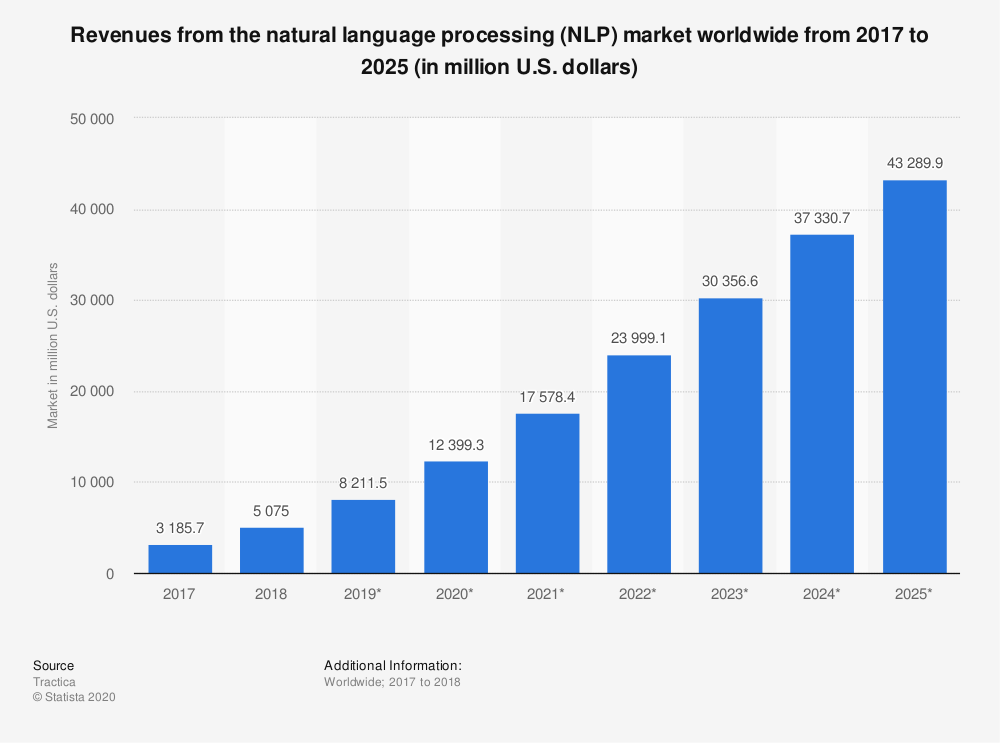
從 2018 年到 2025 年,NLP 技術市場預計將增長 750% 以上……
GPT-3(及其後代)等 NLG 模型對環境的影響可能會隨之增加。
人工智能研究人員非常清楚對環境的潛在破壞,並正在採取措施來衡量和減少它。
但是,儘管科學家做出了最大努力,但氣候變化對人類(和地球)構成的“生存威脅”意味著人工智能技術對全球變暖的任何加劇都不應掉以輕心。
GPT-3 和 SEO
內容是數字營銷的命脈……
因此,難怪眾多 NLG 初創公司都以 SEO 為目標。
人工智能已經對作家如何創建 SEO 驅動的內容產生了重大影響——想想 Surfer 和 PageOptimizerPro……
但是,有哪些應用聲稱可以完全消除對作家的需求?
或者一個應用程序可以編寫與您自己編寫的電子郵件沒有區別的電子郵件?
很容易看出內容創建自動化平台的吸引力……
特別是如果您創建內容的唯一目標是推動自然搜索流量,並且不擔心為您的讀者提供價值。
許多這樣的應用程序處於測試階段或等待名單階段——但有一些已經開始營業。
我採訪了自動內容創建 SaaS Contentyze 的創始人 Przemek Chojecki,了解他對 NLG 技術發展方向的看法……
我還詢問了 SEO Notebook 創始人 Steve Toth 和 NLP 應用程序開發人員和數據驅動的故事講述者 Aleks Smechov,以收集他們對 NLG 對 SEO 和一般網絡內容的潛在影響的看法。
Prezemek Chojecki
內容化
採訪 Przemek Chojecki — Contentyze 的創始人*
是什麼啟發了您創建 Contentyze?
我自己寫了很多,我最初的目標是建立一套算法,讓我的寫作過程更快更順暢。 那是成功的,所以我決定做一個平台,以便其他人也可以使用它。
誰是您理想的目標客戶?
目前,我的目標受眾是營銷人員和 SEO 專家。 這個群體經常需要大量的內容,Contentyze 可以幫助他們加快流程。 但理想情況下,我希望 Contentyze 對任何需要編寫文本的人有用:學生、辦公室工作人員、內容創建者。 真的任何人!
你能給我一個示例用例嗎?
目前,最常見的用例是從標題生成博客文章或從鏈接生成文本摘要。
第一個用例是這樣工作的:你給 Contentyze 一個提示——比如一個句子或一個問題,比如“如何在企業中使用人工智能?”
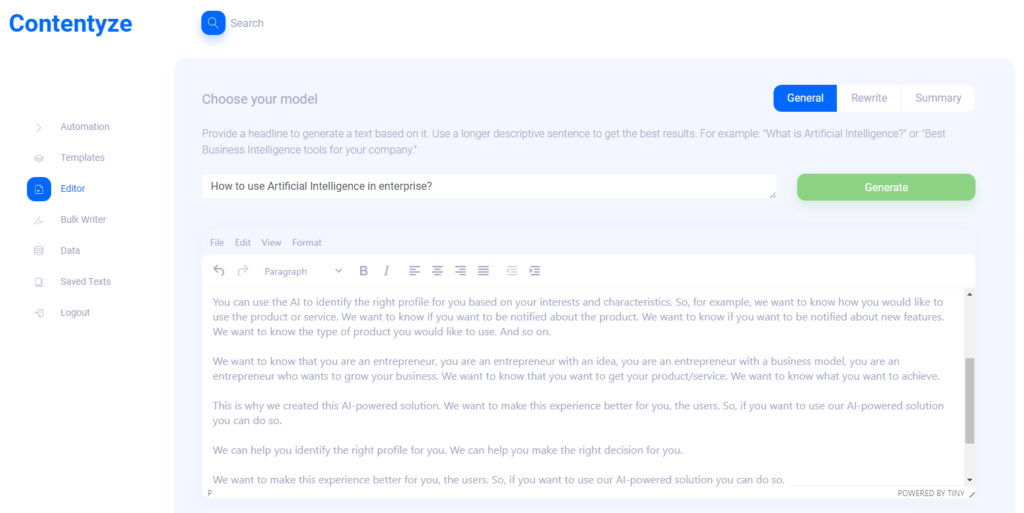
單擊生成,等待 1-2 分鐘,然後獲取文本草稿。
它並不總是理想的,但它總是獨一無二的。 您可以使用相同的提示/標題重複此過程幾次,以獲得更多文本。
然後你挑選,瞧,你的博客上有一個文本。
Contentyze“擅長”什麼樣的內容?
目前,Contentyze 非常擅長總結文本。
它在生成文本方面也相對較好,但還沒有我想要的那麼一致。
Contentyze 不擅長什麼樣的內容?
重寫功能仍然需要做很多工作才能使它變得更好。
我們已經允許人們重寫文本,但我對它現在的工作方式並不滿意。
如果你不想做一個簡單的內容旋轉(去同義詞庫並為接近的東西改變形容詞),那麼進行良好的重寫是相當具有挑戰性的。
您目前是否看到 Contentyze 增加了人類作家/編輯的工作或完全取代它們?
絕對增加了人類作家的作品。 我的最終目標是創建一個完美的寫作助手,可以幫助你在寫作過程的任何階段寫任何東西:從構思到起草和編輯。
可能在這個過程中,一些文案的工作會被取代,儘管這不是我的目標。
我試過 Contentyze 並註意到一些事情。 它(可以預見)在短內容(例如產品評論等)方面表現更好。您認為 Contentyze 在不久的將來會在長內容方面表現更好嗎? 為什麼?
由於我們目前的計算能力有限,它可以更好地處理短內容。 這完全是我們目前正在處理的技術問題。 文本越長,處理它所需的計算能力就越大。
當我要求 Contentyze “重寫”最近關於 SEOButler 的一篇關於 Apple 可能開發搜索引擎以與 Google 競爭的文章時,第一句話是有道理的:
未來幾年,谷歌的搜索引擎可能會受到新競爭對手的威脅。
但這些是以下句子:
蘋果和谷歌正在討論一項可能的交易,谷歌可能會接管這家搜索巨頭在 iPhone 上的搜索功能。
據報導,蘋果將其智能手錶業務出售給三星的交易存在疑問。
據報導,谷歌正在考慮在俄羅斯推出一個新的搜索引擎,以與 Alphabet 的谷歌和微軟的 Bing 等公司競爭。
Apple 最新的 iPhone 7 Plus 是一系列旨在與 Google 的 Android 操作系統競爭的高端智能手機中的最新款。
Bing 是世界上最大的搜索引擎,其搜索結果被全球許多其他搜索引擎使用,包括 Google、Yahoo 和 Microsoft。
如果您想在 Internet 上查找某些內容,則無需為每次搜索使用單獨的搜索引擎。
越深入改寫,就出現了與原文章完全無關的句子:
如果您正在尋找要聽的新歌或要購買的新專輯,您可以在很多地方找到它。
如果您想找到世界上最好的音樂,您現在可以在網上找到它。
以及完全不正確的陳述:
谷歌最新的搜索更新是這家長期落後於微軟和蘋果等競爭對手的搜索巨頭向前邁出的可喜一步。
您如何看待您的最終用戶使用這些類型的結果?
正如我所說,重寫是現在最糟糕的工作功能。 使用摘要選項您不會得到類似的東西。
在使用提示創建新內容時,我得到了類似的結果。 您是否認為 Contentyze 在其發展的這個階段被用作人類作家的頭腦風暴工具,而不是用於準備發布的內容?
是的,我不指望人們在現階段直接在生產層面使用它。
另一方面,快速起草文本非常有用,這樣人工編輯可以對其進行審查,進行必要的更改以確保質量,然後將其發布。
我希望 Contentyze 最終能夠完成 80% 的寫作工作,而人類作家將完成剩下的工作。
我看到 Contentyze 和其他 NLG 初創公司直接向 SEO 和聯盟營銷人員推銷他們的 SaaS 應用程序。 為什麼?
實際上,這是很自然的——這些觀眾經常需要內容,所以他們正在積極尋找可以幫助他們的工具。 Contentyze 在幾乎沒有營銷的情況下增長到超過 3,000 名用戶,幾乎完全是有機地發現的。
您是否認為從長遠來看,人們大規模使用像 Contentyze 這樣的應用程序來生成大量純粹用於 SEO 的內容,而不考慮為讀者提供價值是否存在任何危險? 如果發生這種情況或類似情況,你認為谷歌會修改他們的搜索算法來發現和懲罰人工智能生成的內容嗎?
這就是為什麼 GPT2/GPT3 的創建者 OpenAI 制定了嚴格的政策來監控其算法的使用的原因。 對於 GPT3 及其整個申請流程尤其如此。
我認為我們前進時需要小心,因為這種技術很容易被用來在互聯網上“垃圾郵件”,而不會帶來任何價值。
整個 SEO 遊戲肯定會改變。 谷歌將像以前多次那樣調整其算法,但很難預測會發生什麼。
我的賭注是在未來 3-5 年內,人工智能生成的內容與人類書面內容無法區分,因此如果谷歌想要懲罰人工智能生成的內容,他們將不得不發明其他東西。
無論如何,我不會區分人類內容和人工智能內容。 我們應該只詢問給定的內容是否提供價值,無論是誰或什麼創造了它。
你還有什麼想分享的嗎?
感謝您的採訪,請訪問我們的 contentyze.com — 註冊是免費的(無需信用卡),所以您可以嘗試一下!
我們非常重視反饋,我們希望使我們的工具盡可能好,以便營銷領域的人們可以使他們的工作更有效。
史蒂夫托特
SEO筆記本
採訪 Steve Toth — SEO Notebook 的創始人*
自 SEO Notebook 於 2018 年推出以來,它已成為SEO 必讀的單一運營商通訊。
我們很幸運地讓史蒂夫為 SEOButler 的最後三個專家綜述做出了貢獻,幾年來我一直通過電子郵件與他通信。
我也有幸在清邁 SEO 2019 上見到了史蒂夫。所以當我看到他在 Affiliate SEO Mastermind Facebook 小組上發布關於為 SEO 客戶測試 GPT-3 生成內容的帖子時,我不得不聯繫他的想法……
您如何看待 GPT-3 和其他 NLG 技術在未來幾年對 SEO 的影響?
我認為這會削弱用戶對 Google 的信任。 我認為人們會更多地向他們的朋友尋求建議。
您如何利用 GPT-3 為 SEO 創建支持內容?
慎用。 我有一位客戶想要這樣做。 所以我在指導他們,但這個項目將影響我未來使用它的程度。
在使用 GPT-3 生成的內容時,可讀性對您來說有多重要?
巨大的。 這就是為什麼我認為自己不會過多地推動 GPT-3。
GPT-3 可能在頁外有它的用途,但它並不能完全取代文案。
是否有任何類型的內容(例如,附屬網站的產品評論)在不久的將來 NLG 會取代人類作家?
人們可能會使用 GPT-3 內容構建整個附屬網站,然後等待查看排名並稍後改進副本。 我認為這是主要的用例。
阿列克斯·斯梅喬夫
Skriber.io
採訪 Aleks Smechov — Skriber.io 創始人和 NLP SaaS 開發人員*
作為 SEOButler 博客的貢獻者和 The Edge Group 的時事通訊顧問,Aleks 還是 NLP SaaS 應用程序 Extractor 和 Skriber 的創始人/開發者。
您是否看到 GPT-3 或其他 NLG 技術在不久的將來取代某些類型內容的作者和編輯?
我將專注於新聞方面。
已經有非人工智能軟件正在創建基於事實的小型文章。
一個例子是自動洞察以及他們如何編寫 NCAA 籃球報導和排序。
我認為,如果您將 NLG 與基於模板的文本生成相結合,您可以創建更重要/更長的故事或聚合其他故事的部分。
但對於更嚴肅的新聞業,我只看到人工智能在促進新聞編輯室,而不是取代它。
即使使用 GPT-3 或其他大型自然語言模型,除了需要大量的事實檢查之外,獲得一個好的句子或段落就像輪盤賭。
這比讓記者寫這篇文章更費力。
您是否認為 NLG 在不久的將來會增強內容創建者的角色? 如果是這樣,怎麼做?
當然,為了創建已經寫好的句子/段落的替代品,總結,或者像上面提到的那樣,聚合來自多個來源的內容(例如,對於綜述,無論如何可能都需要編輯)。
對於 GPT-3 等 NLG 技術的普及,您最擔心的 3 個問題是什麼?
NLG 使用以下內容填充互聯網:
- 不實垃圾
- 臃腫的 SEO 內容
- 看起來與其他所有內容非常相似的內容。
並不是說這些東西還沒有出現在互聯網上...... <笑臉表情符號>
我可以解僱我的作家和編輯嗎?
這是簡短的回答:不。
人工智能已經證明自己在狹窄的特定任務上與人類相同或優於人類——從擊敗世界上最偉大的國際象棋和圍棋選手到檢測癌症。
但是,儘管 NLG 在模仿自然語言方面變得非常出色,但要取代熟練的人類作家和編輯還有很長的路要走。
即使是最複雜的 NLG 也依賴於人類的“提示”——更不用說密集的編輯和事實檢查了……
創造力——尤其是與提出原創想法以及在不同的信息和靈感來源之間建立獨特聯繫相關時——不是 GPT-3 的一部分。
GPT-3 可以模仿描述世界、情感和體驗的文本——但它沒有自己的東西。
以下是 GPT-3 本身對這個問題的看法……
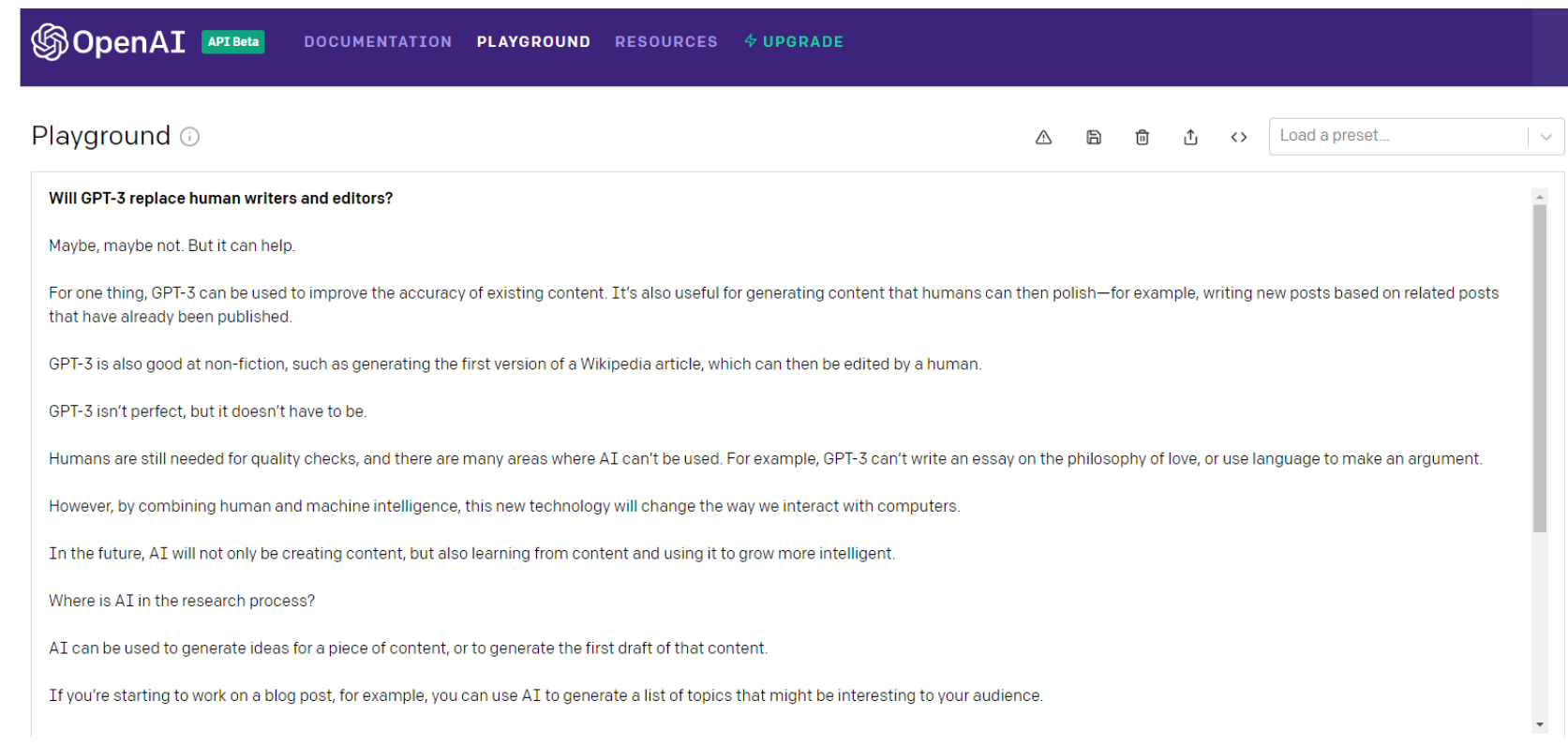
等等,讓我們再問一遍……
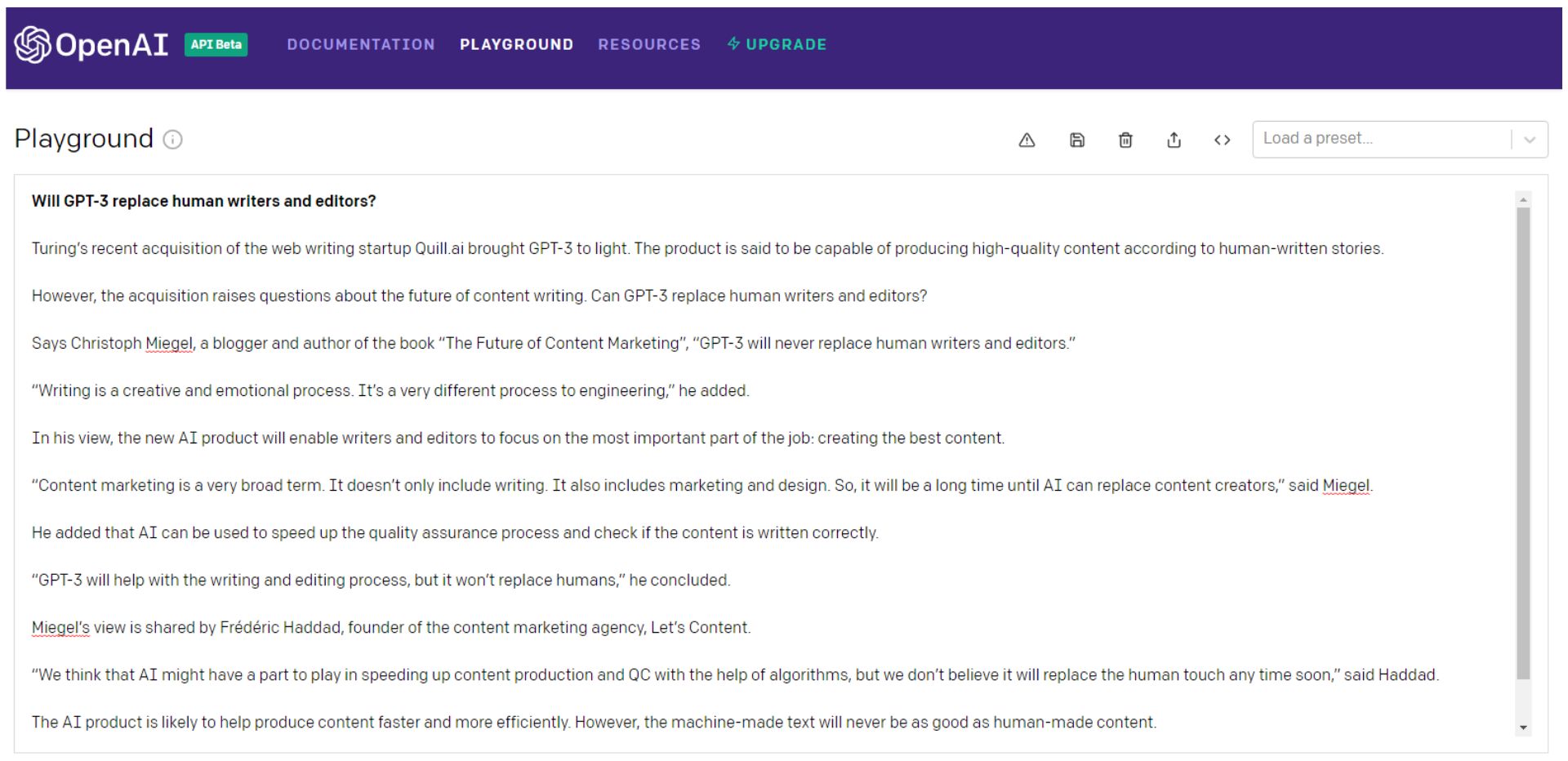
當然,您可以繼續擲 GPT-3 骰子(我更願意將其視為俄羅斯輪盤賭),挑選最好的部分,然後將其拼接成比科學怪人怪物的內容更好的東西。
最好是具有連貫觀點的拼湊而成,可以真正吸引您的觀眾。

那麼科學怪人就需要徹底的事實核查。
請注意,即使是第二個示例中的第一句話也是一個垃圾詞沙拉。
Alan Turing 已經去世 66 年了——他是否正在收購“網絡寫作初創公司”是值得懷疑的。
或者這是對微軟圖靈 NLG 的引用? 不管怎樣,它肯定沒有收購一家公司,也沒有讓 GPT-3 曝光。
你可以做所有這些——或者你可以僱一個作家。
GPT-3 及其後代——或任何其他 NLG 模型——在取代作家和編輯之前必須變得更加聰明。
而且更人性化。

通用人工智能(AGI)——比人類更人性化?
NLP 和 NLG 可能(也可能不會)成為通向通用人工智能 (AGI) 道路上的關鍵步驟。
長期以來被認為是人工智能的聖杯,AGI 機器就是你在電影中看到的機器——“機器人”可以做任何人類可以做的事情,甚至更好。
OpenAI 無疑將目光投向了創造 AGI。 在宣布微軟向 OpenAI 投資 10 億美元時,該公司是這樣定義的:
“AGI 將是一個系統,能夠將一個研究領域掌握到世界專家的水平,並且比任何人都掌握更多的領域——就像一個結合了居里、圖靈和巴赫技能的工具。
解決問題的 AGI 將能夠看到人類無法看到的跨學科聯繫。 我們希望 AGI 與人們合作解決當前棘手的多學科問題,包括氣候變化、負擔得起的高質量醫療保健以及個性化教育等全球挑戰。
我們認為它的影響應該是給予每個人經濟自由去追求他們認為最有成就感的事情,為我們所有人的生活創造今天難以想像的新機會。”
聽起來像烏托邦,對吧?
但這是一件好事嗎?
從歷史上看,烏托邦根本沒有成功:
“當不完美的人嘗試完美——個人的、政治的、經濟的和社會的——他們失敗了。 因此,烏托邦的黑暗鏡子是反烏托邦——失敗的社會實驗、壓制性的政治制度以及由烏托邦夢想付諸實踐的霸道經濟體系。” ——邁克爾·舍默
以下是 GPT-3 對實現 AGI 的評價:

這可能只是一廂情願,GPT-3,但這次我傾向於同意。

增強作家——而不是取代他們
GPT-3 在上述示例的最後一句話中再次可以說是錯誤的……
在 NLP、NLG 甚至對 AGI 的探索上,都取得了實質性的進展。
而且創新的步伐不會很快放緩。
Less than a month into 2021, the Google Brain team announced a new transformer-based AI language model that dwarfs GPT-3 when measured by the number of parameters.
Google's Switch Transformer is trained on 1 trillion parameters — roughly 6 times as many as GPT-3.
Little is known about potential applications for the Switch Transformer model at the time of writing, but the NLP arms-race shows no signs of abating.
Maybe the day will come when machines replace human writers and editors, but I'm not holding my breath.
As Tristan Greene, AI editor for The Next Web, says about Switch Transformer:
“While these incredible AI models exist at the cutting-edge of machine learning technology, it's important to remember that they're essentially just performing parlor tricks.
These systems don't understand language, they're just fine-tuned to make it look like they do.”
At this point, I'm sure it's clear that I have a dog in this fight.
As objective as I've tried to be in writing this article, I do have a vested interest in human content creators remaining relevant and superior to machines.
But that doesn't mean I don't see how NLP and NLG technology can make me better at what I do.
In truth, AI has been augmenting my writing and editing for years…
I use Rev to auto-transcribe audio and video interviews. I also use it to create transcripts of SEOButler founder Jonathan Kiekbusch and Jarod Spiewak's Value Added Podcast to help me write the show notes more quickly and accurately.
And Grammarly is a powerful tool for even the most diligent editor or proofreader.
As GPT-3 and other advanced NLP models become more accurate and “trustworthy,” their potential ability to summarize long-form content — particularly academic research papers — could prove extremely valuable.
Suppose the future I have to look forward to is one where AI eliminates some of the drudgery of creating SEO-driven content — and I have to edit and polish informational content partly composed by machines instead of writers.
I guess I can live with that…
I may not have a choice.
*Each Q&A has been edited and condensed for clarity.