
如何在內容營銷中使用 NLP
已發表: 2022-05-02Trust Insights 的聯合創始人 Chris Penn 和 MarketMuse 的聯合創始人兼首席產品官 Jeff Coyle 討論了人工智能營銷的商業案例。 網絡研討會結束後,Paul 參加了我們的 Slack 社區內容策略集體(在此處加入)中的“隨便問我”會議。 以下是網絡研討會筆記和 AMA 的文字記錄。

網絡研討會
問題
隨著內容的爆炸式增長,我們有了新的中介。 他們不是記者或社交媒體影響者。 它們是算法; 機器學習模型決定了你和你的觀眾之間的一切。
如果不考慮這一點,您的內容將繼續陷入默默無聞的泥潭。
解決方案:自然語言處理
NLP 是計算機編程來處理和分析大量自然語言數據。 這來自文檔、聊天機器人、社交媒體帖子、您網站上的頁面以及任何其他本質上是一堆單詞的東西。 基於規則的自然語言處理首先出現,但被統計自然語言處理所取代。
NLP 的工作原理
自然語言處理的三個核心任務是識別、理解和生成。
識別——計算機不能像人類一樣處理文本。 他們只能閱讀數字。 所以第一步是將語言轉換成計算機可以理解的格式。
理解——將文本表示為數字使算法能夠進行統計分析,以確定哪些主題最常一起被提及。
生成——在分析和數學理解之後,NLP 的下一個合乎邏輯的步驟是文本生成。 機器可用於呈現作者需要在其內容中回答的問題。 在另一個層面上,人工智能可以推動內容簡介,為創建專家級內容提供額外的洞察力。
這些工具今天可通過 MarketMuse 購買。 除此之外,還有你今天可以使用的自然語言生成模型,但它們還沒有商業上可用的形式。 儘管 MarketMuse NLG 技術很快就會到來。
提到的其他資源
- 擁抱臉.co
- Python
- R
- Colab
- IBM 沃森工作室

美國醫學會
你有任何文章或網站推薦來跟上人工智能行業的趨勢嗎?
正在閱讀那裡發表的學術研究。 像這樣的網站都在覆蓋最新和最偉大的方面做得很好。
- KDNuggets.com
- 邁向數據科學
- 卡格爾
Facebook、谷歌、IBM、微軟和亞馬遜的主要研究出版中心。 您會在這些網站上看到大量共享的優質材料。
“我正在為我的所有內容使用關鍵字密度檢查器。 對於今天的 SEO 來說,這離合理的策略還有多遠?”
關鍵字密度本質上是術語頻率計數。 它在理解文本的非常粗略的性質方面佔有一席之地,但它缺乏任何語義知識。 如果您無法使用 NLP 工具,請至少在您選擇的 SEO 工具中查看諸如“人們也搜索過”內容之類的內容。
您能否就如何將內容生成到……網頁中給出一些具體示例? 帖子? 推文?
挑戰在於這些工具正是如此——它們是工具。 就像,你如何操作抹刀? 這取決於你在做什麼。 你可以用它來攪拌湯,也可以翻煎餅。 開始學習這些知識的方法取決於您的技術水平。 例如,如果您對 Python 和 Jupyter 筆記本感到滿意,您可以直接導入轉換器庫,輸入您的訓練文本文件,然後立即開始生成。 我用某個政客的推文做到了這一點,它開始吐出可能引發第三次世界大戰的推文。如果你在技術上不習慣,那就開始看看 MarketMuse 之類的工具。 我會讓 Jeff Coyle 提供有關普通營銷人員如何從那裡開始的建議。
如果您超越工具,而更多地關注策略,那麼您可以實施以利用這些知識的策略示例是什麼?
一些快速命中的方法是用於元描述、將頁面或內容塊分類到分類中,或者嘗試猜測需要答案的問題——但這些都是真正的點解決方案。 當你用它來展示你當前的優勢、差距以及你有動力的地方時,更大的戰略智慧就會出現。 從那裡開始,決定創建、更新、擴展什麼對企業來說變得具有變革性。 現在想像一下對競爭對手做同樣的事情。 尋找他們的差距。 起泡,沖洗,重複。
戰略始終以目標為基礎。 你想達到什麼目標? 你在吸引搜索流量嗎? 你在做潛在客戶嗎? 你在做公關嗎? NLP 是一堆工具。 它類似於 - 策略是菜單。 您供應早餐、午餐還是晚餐? 您使用的工具和食譜在很大程度上取決於您提供的菜單。 如果你正在製作 spanakopita,湯鍋將毫無幫助。
對於想要開始挖掘數據以獲得洞察力的人來說,什麼是一個好的起點?
從科學的方法開始。
- 你想回答什麼問題?
- 您需要哪些數據、流程和工具來回答這個問題?
- 制定一個假設,一個單一條件,可證明是真的或假的陳述,你可以測試。
- 測試。
- 分析您的測試數據。
- 改進或拒絕假設。
對於數據本身,使用我們的6C數據框架來判斷數據的質量。
在您看來,營銷人員應該考慮的主要搜索用戶意圖是什麼?
客戶旅程中的步驟。 從頭到尾繪製客戶體驗——意識、考慮、參與、購買、所有權、忠誠度、宣傳。 然後繪製出每個階段可能的意圖。 例如,在所有權方面,搜索意圖很可能是面向服務的。 “如何修復 airpods pro 劈啪聲”就是一個例子。 挑戰在於在旅程的每個階段收集數據並使用它來訓練/調整。
你不覺得這可能有點不穩定嗎? 如果我們需要更穩定的東西來自動化流程,那麼我們需要在更高的層次上概括事物。
傑夫·貝索斯(Jeff Bezos)有句名言,專注於不變的事物。 獲得所有權的一般途徑沒有太大變化——對他們的口香糖包不滿意的人會遇到與對他們委託的新核航空母艦不滿意的人類似的事情。 細節肯定會發生變化,但了解哪些類型的數據和意圖對於了解某人在旅途中的情感位置以及他們如何用語言傳達這一點至關重要。
人們在嘗試進行用戶意圖分類時可能會陷入哪些陷阱?
到目前為止,確認偏差。 人們會將自己的假設投射到客戶體驗上,並通過自己的偏見來解釋客戶數據。 我還建議您盡可能使用交互數據(打開的電子郵件、進門、呼叫呼叫中心等)來驗證它。 我知道有些地方,尤其是大型組織,是結構化方程建模的忠實擁護者,以了解用戶意圖。 我不像他們那麼喜歡,但這是一種額外的潛在方法。
您認為哪些工具或產品可以很好地確定查詢的用戶意圖?
緯。 除了 MarketMuse? 老實說,我不得不使用自己的東西,因為我沒有找到很好的結果,尤其是來自主流 SEO 工具。 FastText 用於矢量化和非結構化聚類。
根據您的經驗,BERT 是如何改變 Google 搜索的?
BERT 的主要貢獻是上下文,尤其是修飾符。 BERT 允許谷歌查看詞序並讓它解釋含義。 在此之前,這兩個查詢在詞袋樣式模型中可能在功能上是等效的:
- 最好的咖啡店在哪裡
- 哪裡是買咖啡的最佳地點
這兩個查詢雖然非常相似,但可能會產生截然不同的結果。 咖啡店可能不是你想買豆子的地方。 沃爾瑪絕對不是你想喝咖啡的地方。
你認為人工智能或信息通信技術會像人類一樣發展意識/情感/同理心嗎? 我們將如何對它們進行編程? 我們如何使人工智能人性化?
答案取決於量子計算會發生什麼。 Quantum 允許可變的模糊狀態和模擬我們自己大腦中正在發生的事情的大規模並行計算。 你的大腦是一個非常緩慢的、基於化學的大型並行處理器。 它真的很擅長一次做很多事情,如果不是很快的話。 量子將允許計算機做同樣的事情,但速度要快得多——這為通用人工智能打開了大門。 這是我的擔憂,這也是今天對人工智能的擔憂,已經在狹隘的使用範圍內:我們基於我們訓練它們。 人類在善待自己或我們賴以生存的星球方面做得併不好。 我們不希望我們的計算機模仿這一點。
我懷疑在系統允許的範圍內,計算機情緒在功能上將與我們自己的情緒大不相同,並且會從它們的數據中自我組織,就像我們對基於化學的神經網絡所做的那樣。 這反過來意味著他們的感覺可能與我們大不相同。 如果機器主要基於邏輯和數據,對人類進行坦誠、客觀的評估,坦率地說,他們可能會確定,我們遇到的麻煩多於我們的價值。 坦率地說,他們不會錯的。 作為一個物種,我們大多數時候都是野蠻的混亂。
在您看來,您如何看待內容營銷人員將自然語言生成集成/採用到他們的日常工作流程/流程中?
營銷人員應該已經在整合它的某種形式,即使它只是回答我們在 MarketMuse 產品中演示的問題。 回答您知道觀眾關心的問題是創建有意義的內容的一種快速、簡單的方法。 我的朋友馬庫斯·謝里丹(Marcus Sheridan)寫了一本很棒的書,“他們問,你回答”,具有諷刺意味的是,您實際上並不需要閱讀它來掌握核心客戶策略:回答人們的問題。 如果您還沒有真人提交的問題,請使用 NLG 來製作它們。

您認為未來 2 年 AI 和 NLP 會在哪些方面取得進展?
如果我知道這一點,我就不會在這裡,因為我會在我用我的收入購買的山頂堡壘。 但嚴肅地說,我們在過去 2 年中看到的沒有任何變化跡象的主要支點是從“滾動你自己的”模型到“下載預訓練和微調”的進展。 我認為隨著機器在合成方面的進步,我們將迎來視頻和音頻領域的一些激動人心的時刻。 尤其是音樂生成,對於自動化來說已經成熟了。 現在,機器充其量只能產生完全平庸的音樂,而最壞的情況是產生耳痛。 這種情況正在迅速改變。 我看到了更多的例子,比如像 BART 一樣將變壓器和自動編碼器混合在一起,作為模型進展和最先進結果的主要下一步。
你認為谷歌在信息檢索方面的研究方向是什麼?
谷歌繼續面臨的挑戰是規模,你可以在他們的許多研究論文中看到這一點。 他們尤其受到 YouTube 等內容的挑戰; 他們仍然嚴重依賴二元組這一事實並不是對他們的成熟度的打擊,而是承認除此之外的任何東西都會產生瘋狂的計算成本。 他們的任何重大突破都不會是模型層面的,而是規模層面的,以應對每天湧入互聯網的大量新的、豐富的內容。
你遇到過哪些最有趣的人工智能應用?
自主一切是我密切關注的一個領域。 深度偽造也是如此。 如果我們不小心,它們就是前方道路有多危險的例子。 特別是在 NLP 中,生成正在快速發展,是值得關注的領域。
您在哪裡見過 SEO 以不起作用或不起作用的方式使用 NLP?
我已經數不清了。 很多時候,人們以非預期的方式使用工具並獲得低於標準的結果。 就像我們在網絡研討會上提到的那樣,有針對模型的不同最先進測試的記分卡,並且在不強大的領域使用工具的人通常不會喜歡結果。 也就是說……除了供應商提供的東西之外,大多數 SEO 從業者沒有使用任何類型的 NLP,而且許多供應商仍然停留在 2015 年。一直都是關鍵字列表。
您在 Google 哪裡看到視頻 (YouTube) 和圖片搜索? 您認為 Google 部署的用於所有類型搜索的技術彼此之間是否非常相似或不同?
谷歌的技術都建立在他們的基礎設施之上並使用他們的技術。 很多東西都建立在 TensorFlow 之上,這是有充分理由的——它超級健壯且可擴展。 不同之處在於谷歌如何使用不同的工具。 與用於成對比較和語言處理的 TensorFlow 相比,用於圖像識別的 TensorFlow 本質上具有非常不同的輸入和層。 但是,如果您知道如何使用 TensorFlow 和那裡的各種模型,您可以自己實現一些非常酷的東西。
我們可以通過哪些方式適應/跟上 AI 和 NLP 的進步?
繼續閱讀、研究和測試。 弄髒你的手是無可替代的,至少是一點點。 註冊一個免費的 Google Colab 帳戶並嘗試一下。 自學一點 Python。 從 Stack Overflow 複製和粘貼代碼示例。 你不需要知道內燃機的每一個內部工作來駕駛汽車,但是當出現問題時,一點點的知識就會有很長的路要走。 在 AI 和 NLP 中也是如此——即使只是能夠打電話給供應商 BS 也是一項寶貴的技能。 這是我喜歡與 MarketMuse 人員一起工作的原因之一。 他們實際上知道他們在做什麼,他們的人工智能工作不是廢話。
你會對那些擔心人工智能會搶走他們的工作的人說些什麼? 例如,看到 NLG 之類的技術的作家擔心如果 AI 可以“足夠好”讓編輯稍微清理一下文本,他們就會失業。
“人工智能將取代任務,而不是工作”——布魯金斯學會這絕對是真的。 但是將會有淨工作崗位流失,因為這就是將會發生的事情。 假設您的工作由 50 個任務組成。 AI 做了其中的 30 個。 太好了,您現在有 20 個任務。 如果你是唯一這樣做的人,那麼你就處於涅槃狀態,因為你還有 30 多個單位的時間來做更有趣、更有趣的工作。 這就是 AI 樂觀主義者所承諾的。現實檢查:如果有 5 個人在做這 50 個單位,而 AI 做其中的 30 個,那麼 AI 現在正在做 150 / 250 個單位的工作。 這意味著還有100個工作單元留給人們去做,而公司就是這樣,他們將立即裁員3個職位,因為這100個工作單元可以由2個人完成。你應該擔心人工智能搶走工作嗎? 這取決於工作。 如果您所做的工作令人難以置信地重複,絕對要擔心。 在我以前的機構,有一個可憐的草皮,他的工作是每天 8 小時將搜索結果復制並粘貼到客戶的電子表格中(我在一家公關公司工作,而不是技術最先進的地方)。 這份工作正處於直接危險之中,坦率地說應該已經存在多年了。重複 = 自動化 = 人工智能 = 任務丟失。 你的工作重複性越少,你就越安全。
每一次變化也造成了越來越多的收入不平等。 我們現在正處於一個危險的時刻,機器——不花錢,不是消費者——正在為花錢、消費的人做越來越多的工作,我們在技術領域的巨大財富主導地位中看到了這一點。 這是我們將不得不在某個時候解決的社會問題。
隨之而來的挑戰是進步就是力量。 正如羅伯特·英格索爾(Robert Ingersoll)所寫(後來被誤認為是亞伯拉罕·林肯):“幾乎所有的人都能忍受逆境,但如果你想檢驗一個人的性格,就給他權力。”我們看到今天的人們是如何處理權力的。
如何將 Google Analytics 數據與 NLP Research 配對?
GA代表方向,NLP代表創造。 什麼流行? 我剛剛為一個客戶做了這個。 他們有數千個網頁和聊天會話。 我們使用 GA 分析哪些類別在他們的網站上增長最快,然後使用 NLP 處理這些聊天日誌,向他們展示什麼是趨勢以及他們需要創建什麼內容。
谷歌分析非常適合告訴我們發生了什麼。 NLP 可以開始梳理出一點 WHY,然後我們通過市場研究來完成它。
我已經看到您在許多研究中使用 Talkwalker 作為數據源。 我應該考慮哪些其他來源和用例進行分析?
所以,這麼多。 Data.gov. 說話的人。 市場繆斯。 Otter.ai 用於轉錄您的音頻。 Kaggle 內核。 谷歌數據搜索——順便說一句,它是 GOLD,如果你不使用它,你絕對應該使用它。 谷歌新聞和 GDELT。 那裡有很多很棒的資源。
在您看來,營銷和數據分析團隊之間的理想合作是什麼樣的?
不開玩笑; Katie Robbert 和我一直在客戶身上看到的最大錯誤之一是組織孤島。 左手不知道右手在做什麼,到處都是一團糟。 讓人們聚在一起,分享想法,分享待辦事項,進行共同的站立會議,互相教導——從功能上講,“一個團隊,一個夢想”是理想的合作,以至於你不再需要使用合作這個詞了. 人們只是一起工作,把他們所有的技能帶到桌面上。
您能否回顧一下您在演示文稿中經常預覽的 MVP 報告以及它是如何工作的?
MVP 報告代表最有價值的頁面。 它的工作方式是從谷歌分析中提取路徑數據,對其進行排序,然後通過馬爾可夫鏈模型確定哪些頁面最有可能幫助轉化。
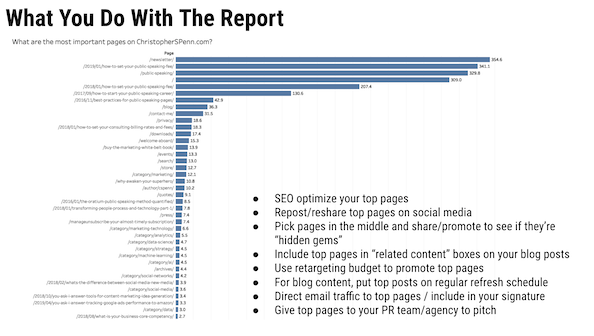
如果你想要更長的解釋。
您能否更深入地了解數據偏差? 構建 NLP 或 NLG 模型時有哪些注意事項?
哦是的。 這裡有很多話要說。 首先,我們需要確定什麼是偏見,因為有兩種基本類型。
人們普遍認為,人類偏見被定義為“與其他事物相比,支持或反對某事的偏見,通常以一種被認為不公平的方式。”
然後是數學偏差,通常被接受定義為“如果一個統計數據的計算方式與被估計的總體參數係統性地不同,那麼它就是有偏差的。”
它們不同但相關。 數學偏差不一定是壞事。 例如,如果您有任何商業意識,您絕對希望偏向於最忠實的客戶。 人為偏見在不公平的意義上是隱含的壞事,尤其是針對任何被認為是受保護的階級:年齡、性別、性取向、性別認同、種族/民族、退伍軍人身份、殘疾等。這些是你不能歧視。
人為偏見會導致數據偏見,通常在 6 個地方:人、策略、數據、算法、模型和行動。 我們僱傭有偏見的人——只要看看一家公司的高管層或董事會,就可以確定它的偏見是什麼。 前幾天,我看到一家公關公司吹捧其對多元化的承諾,並且一鍵點擊他們的執行團隊,他們是一個種族,全部 15 個。
我可以繼續討論這個問題,但我建議你參加我在營銷 AI 學院就這個主題開發的課程。 在 NLG 和 NLP 模型方面,我們必須做一些事情。
首先,我們必須驗證我們的數據。 它是否有偏見,如果有,是否歧視受保護的階級? 其次,如果它是歧視性的,是否有可能減輕它,或者我們必須把數據扔掉?
一種常見的策略是將元數據翻轉為 debias。 例如,如果您有一個包含 60% 男性和 40% 女性的數據集,您可以將 10% 的男性重新編碼為女性,以平衡模型訓練。 這是不完美的並且有一些問題,但它比任由偏見更好。
理想情況下,我們在模型中構建了可解釋性,允許我們在過程中運行檢查,然後我們還驗證結果(可解釋性)事後。 如果您希望能夠通過審核以證明您沒有在模型中建立偏見,那麼兩者都是必要的。 Woe 是一家只有事後解釋的公司。
最後,您絕對需要對多元化和包容性團隊進行人工監督,以驗證結果。 理想情況下,您使用第三方,但可以使用受信任的內部方。 該模型及其結果是否呈現出與您從總體本身得到的結果不同的結果?
例如,如果您正在為 16-22 歲的人創建內容,並且您在生成的文本中沒有看到過像 deadass、dank、low-key 等術語,那麼您就無法在輸入端捕獲任何數據這將訓練模型準確地使用他們的語言。
這裡最大的主要挑戰是通過非結構化數據處理所有這些。 這就是血統如此重要的原因。 沒有血統,您無法證明您對總體進行了正確的抽樣。 沿襲是您記錄數據源是什麼、來自何處、如何收集、是否適用任何監管要求或披露的文檔。
你現在應該做什麼
當您準備就緒時……我們可以通過以下 3 種方式幫助您更快地發布更好的內容:
- 與 MarketMuse 預約時間 與我們的一位策略師安排現場演示,了解 MarketMuse 如何幫助您的團隊實現其內容目標。
- 如果您想了解如何更快地創建更好的內容,請訪問我們的博客。 它充滿了幫助擴展內容的資源。
- 如果您認識其他喜歡閱讀此頁面的營銷人員,請通過電子郵件、LinkedIn、Twitter 或 Facebook 與他們分享。