
NLU 引擎基準測試:面向 AI 市場領導者的數據驅動方法
已發表: 2022-09-09自然語言理解 (NLU) 引擎是巨大的客戶情緒驅動因素。 AI 和 NLU 發展得如此之快,以至於一名谷歌員工聲稱該公司的聊天機器人 LaMDA 是一個有自我意識的人,從而引起了全球的關注。
但別擔心。 我們不是來用人工智能機器人接管世界的故事或客戶服務來嚇唬你的。
大約71% 的美國消費者在他們的客戶服務對話中仍然更喜歡人性化,這就是基準 NLU 引擎進入畫面的地方。
NLU 可以通過在客戶交互中添加知識、上下文和情感層來幫助座席更好地理解和服務客戶。 在基準 NLU 引擎的支持下,對話式 AI 讓品牌變得更加智能和善解人意,並發現隱藏的客戶線索,使客戶服務更加個性化,不像機器。
但是,您如何對 NLU 引擎進行基準測試以評估其 AI 能力? 要到達那裡,讓我們首先了解關鍵技術術語。
NLU 引擎基準測試詞彙表
對話式人工智能
對話式 AI是一種 NLU 支持的功能,它使計算機和數字應用程序能夠通過識別人類對話背後的情感、緊迫性和上下文來吸引客戶。數據集
數據集是計算機可以將其作為單個信息集處理的相關信息集的集合。發聲
話語是通過文本、音頻或視頻接收到的用戶語音的短語或句子。 NLU 引擎使用話語來訓練、測試和解釋用戶意圖。意圖
意圖表示用戶在動作、事件或語句背後的目標。 例如,用戶操作可以分類為產品查詢、投訴、退款請求等。準確性
準確率是 NLU 引擎與正確意圖匹配的測試句子的百分比。F1 宏
每個意圖的精度和召回率的宏觀平均值的調和平均值稱為 F1 宏。
精度= 對意圖的真陽性結果的數量/對意圖的所有陽性結果。
召回率 = 對意圖的真陽性結果數/被確定為對意圖陽性的結果數。
NLU 引擎基準測試:了解流程
比較 NLU 引擎可能是一個乏味的過程。 將一組支持 NLU 的解決方案列入候選名單並進行練習以測試在您的客戶中觀察到的常見意圖可能會很耗時。 這就是由研究支持的結構化方法派上用場的地方,可以用無偏見的方法評估 NLU 引擎及其AI 直覺能力。
用於構建會話代理的自然語言理解服務基準測試
這種 NLU 基準測試方法比較家庭自動化機器人數據集上的 NLU 引擎,將其分解為小型和大型數據集,以評估不同訓練和測試數據大小的機器學習準確性。
NLU 基準測試方法中使用的方法
小數據集
隨機選擇 64 個不同的意圖
每個意圖使用 10 個例句來訓練 NLU 引擎
測試了 1,076 個例句(不屬於訓練集)
大型數據集
為大型數據集挑選了上述相同的 64 個意圖
每個意圖使用大約 30 個例句來訓練 NLU 引擎
測試了 5,518 個例句(不屬於訓練集)
NLU 引擎基準測試報告:結果
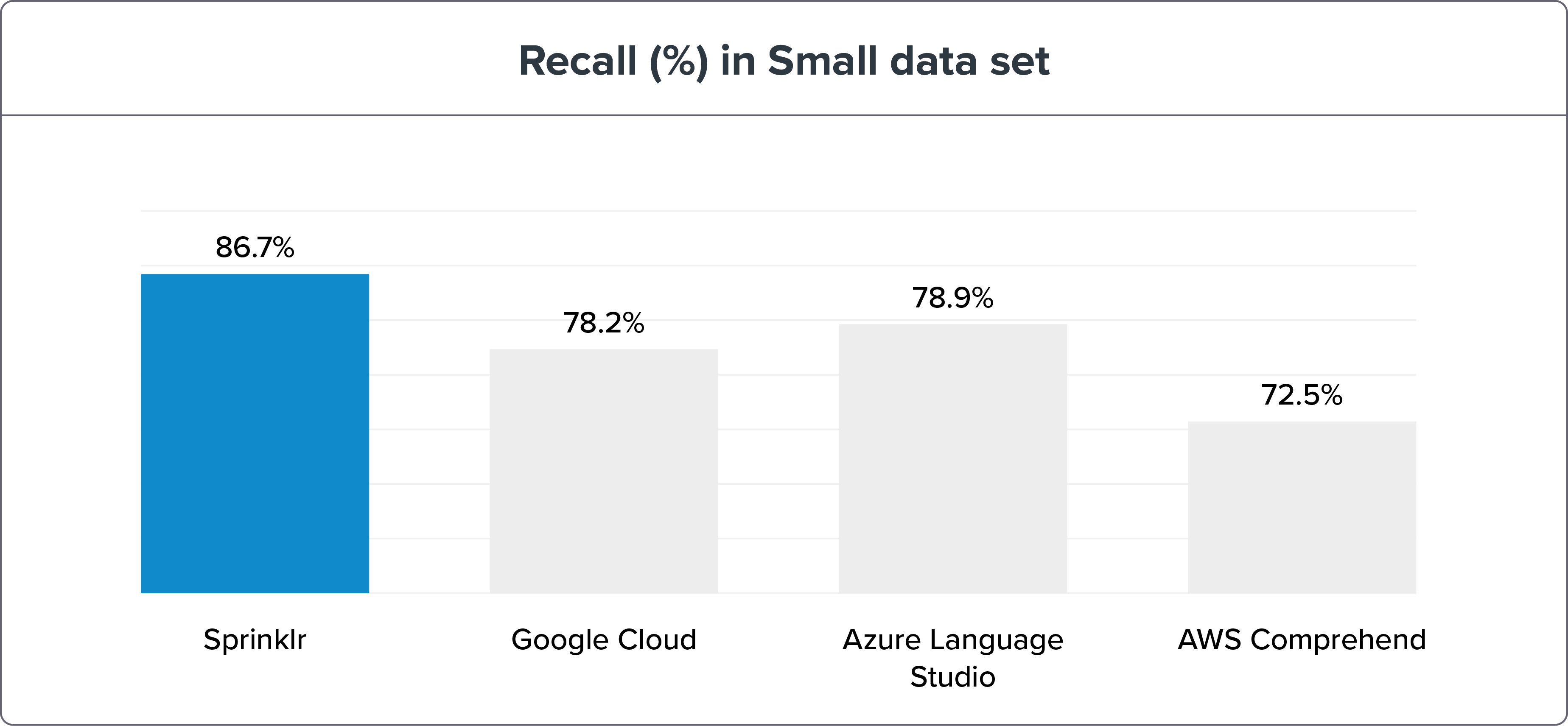
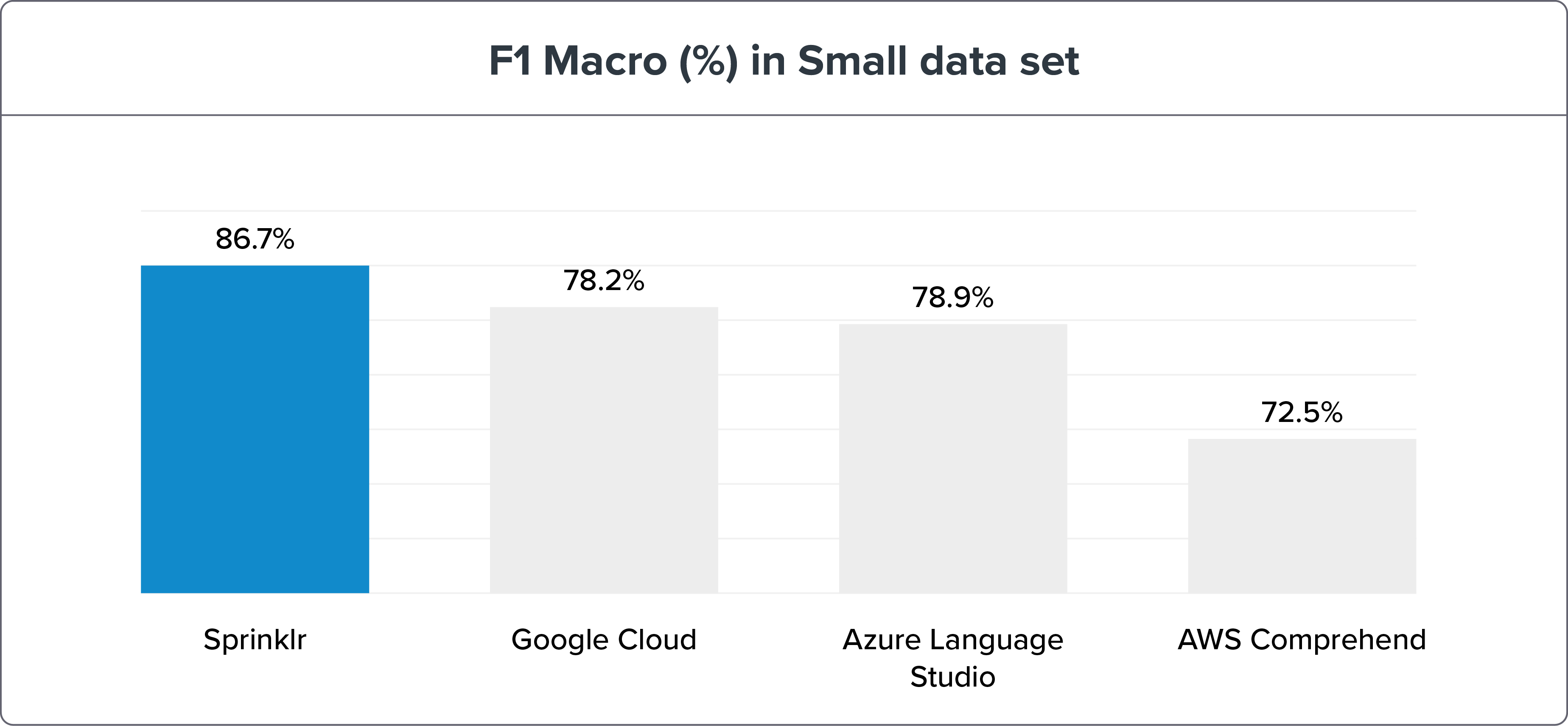
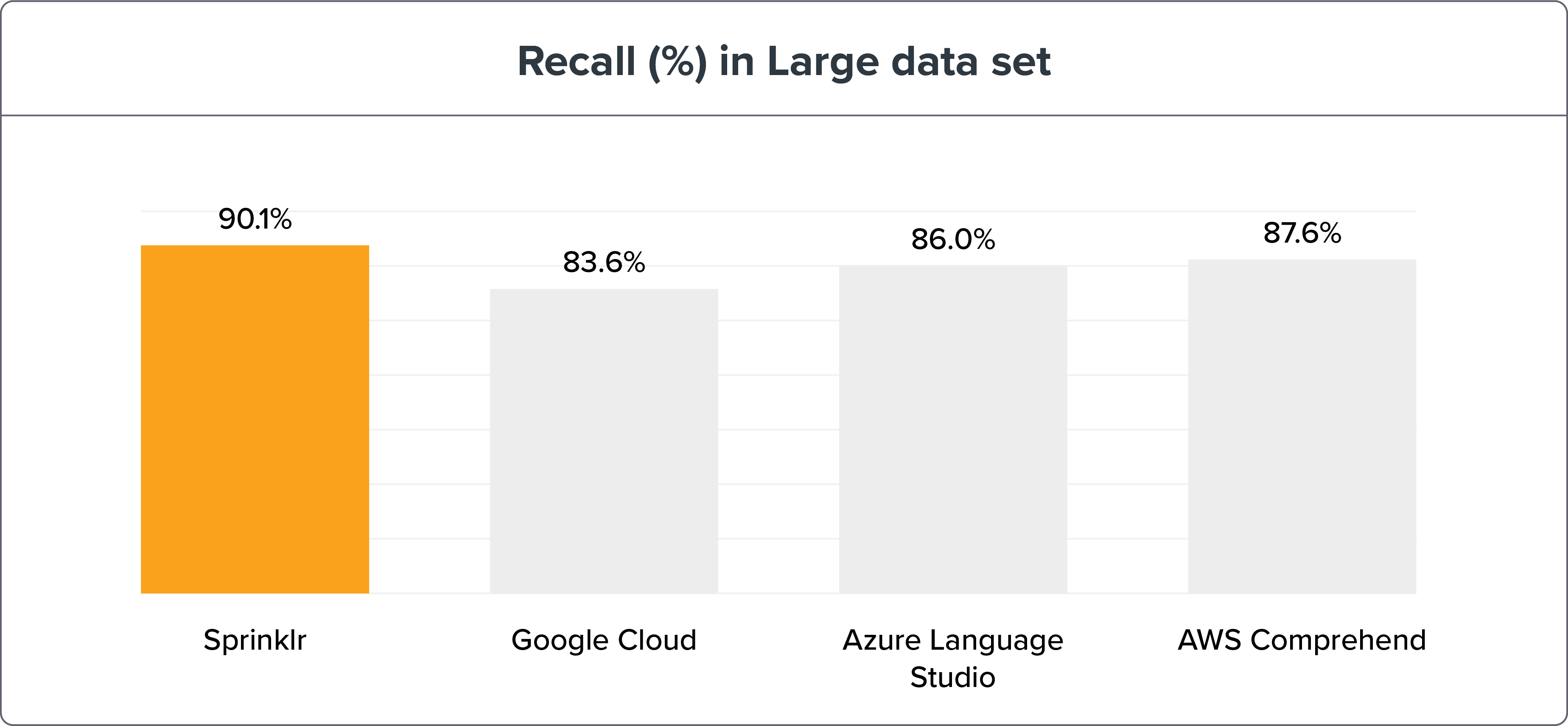
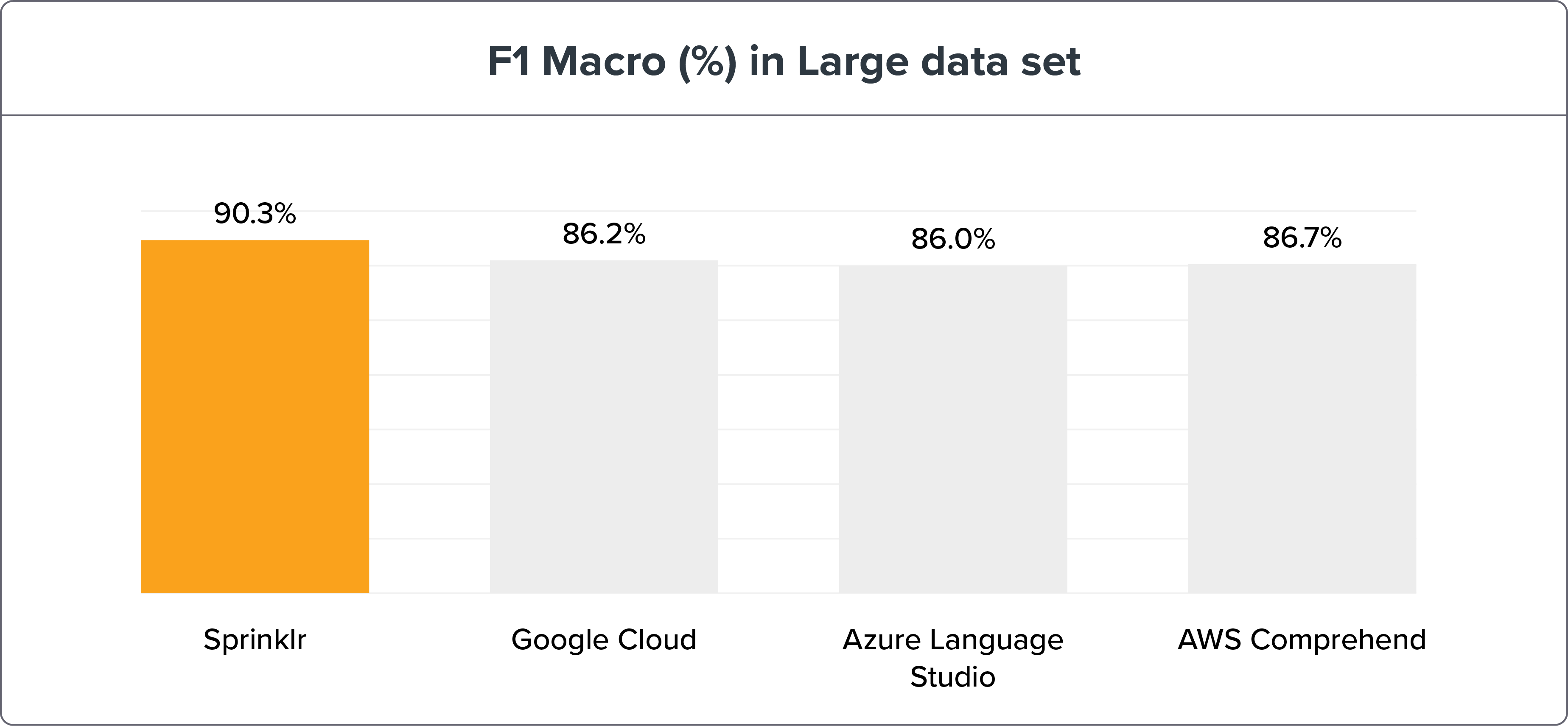
NLU 基準測試方法顯示 Sprinklr 的 NLP 準確性憑藉召回和 F1 宏遠高於其同時代產品——谷歌云、Azure 語言工作室和 AWS Comprehend。 可以在此處找到基準測試數據和結果。
如果我們將 NLU 引擎基準測試分解為小型和大型數據集,Sprinklr NLU 引擎仍然是明顯的贏家。
注意:更大的數據集是測試和訓練意圖以獲得更高準確性的最佳方式。 但是 Sprinklr 的 NLU 引擎的精度變化只有 ≤ 3%。
小數據集
參數:
640 個訓練句子 = 每個 Intent 10 個句子
1,076 個測試句子
大型數據集
參數:
1,908 個訓練句子 ≈ 每個 Intent 30 個句子
5,518 個測試句子
Sprinklr 成為 NLU 引擎基準測試的明顯贏家
Sprinklr 的 NLU 引擎在確定查詢意圖時保持一致和準確,測試輸入和訓練輸入之間的映射更好。
示例 1:小型數據集
問:有什麼需要注意的嗎
基本事實:calendar_query

示例 2:大型數據集
查詢:歐盟有多少個國家
基本事實:qa_factoid

NLU 引擎基準測試的局限性
數據集的大小:由於使用了大量經過充分研究的數據集,NLU 引擎可能比通常發現的原始結構化數據更快地從測試話語中學習。

使用的語言:僅使用英語來測試不同的實例和意圖。
測試數據的性質:用戶的話語聽起來可能不像典型的客戶,他們可能會犯更多的語法錯誤並有對話間隙。
最常見的 NLU 引擎解釋挑戰
典型的 NLU 引擎具有一定的局限性,尤其是在解釋客戶交互時。 以下是最常見的 NLU 引擎解釋錯誤以及避免它們的策略:
諷刺
NLU 引擎很難檢測出諷刺或消極攻擊性的客戶評論。
如何解決它:克服這個問題的一種方法是在批准自動 NLU 引擎響應之前添加關鍵字,例如“謝謝,哇,隨便什麼”,以通過代理運行。
歧義
有時,人類很難區分句子中的一個詞是用作名詞、動詞還是形容詞。 “hang on”或“put out”等短語動詞也會影響 NLU 引擎的認知。
如何解決:減少歧義的最好方法是繼續訓練 NLU 引擎來處理歧義的句子和短語。 隨著時間的推移,引擎開始通過將測試輸入與真實的用戶交互進行比較來從測試輸入中學習。
在 NLU 引擎和 AI 聊天機器人中減少歧義的其他方法:
利用機器學習模型進行更好的 NLU 訓練:使用上下文相關的機器學習模型,例如來自 Transformers (BERT) 的雙向編碼器表示和來自語言模型 (ELMo) 的嵌入來訓練您的 NLU 引擎。 這些AI 模型考慮了單詞和句子的所有不同表示,並使用額外的文本來填充模棱兩可的用戶條目。
創建適當的提示以仔細檢查語言不確定性:使您的 NLU 引擎能夠提供“消歧”響應,提示用戶從不止一種可能性中選擇正確版本的文本。 這與 Google 的“您的意思是……”提示非常相似,其中包含您的搜索詞的可能變體。
訓練和訓練更多:嚴格訓練您的 NLU 引擎以將信號與噪聲分離。 沒有比使用各種獨特的數據集訓練 NLU 引擎更好的意圖檢測的捷徑。 用戶請求可能包含影響 NLU 引擎意圖標記能力的單詞和句子結構。

語言錯誤
拼寫錯誤和不正確的句子結構會阻止 NLU 引擎準確識別用戶意圖。 雖然語法檢查可以解決基本錯誤,但俚語和口語很難解釋,尤其是在文本到語音和語音分析中。
如何解決:再一次,克服這個問題的關鍵是向 NLU 引擎提供大量不准確的模擬話語,其中充滿了錯誤和錯誤的語言。
域變體
Domain-speak 是另一個不同行業的領域。 醫療保健中的“文檔”可以不同於技術中的“文檔”工作流程。
如何解決:明確定義意圖層次結構可以幫助您的 NLU 引擎確定與客戶響應或話語相關聯的行業或領域。
表徵頂級 NLU 引擎的品質
NLU 引擎的認知能力只是為您的公司評估它們時要考慮的因素之一。 它有助於克服阻礙大規模理解用戶意圖的繁瑣手動工作。
此外,以下是 NLU 引擎中需要注意的一些更重要的品質:
1.速度
NLU 引擎必須快速上交結果,因為對話式 AI 是關於了解客戶意圖以快速準確地做出響應。 處理客戶交互的速度不應降低 NLU 引擎的意圖檢測準確性。
2.垂直化
NLU 引擎有大量的用例,橫跨技術、零售、電子商務、物流和酒店等行業。 對話式 AI 功能應該能夠區分這些行業,並以獨特的方法適應每個解決方案領域。
3. 易用性
尋找包含非技術員工資料的 NLU 引擎。 了解如何測試和訓練數據集不應僅限於質量保證工程師和開發人員。 這是非技術背景的企業主可以自己做的事情。 由無代碼 NLU 引擎提供支持的對話式 AI 是提高采用率和可用性的方法。
4. 可擴展性
隨著 NLU 引擎收集越來越多的數據輸入,它必須在各種區域語義、語言變化和用戶表達的不同實體中訓練自己。 構建一個 NLU 框架,該框架可以處理多種語言並使您的對話式 AI 聊天機器人面向未來。
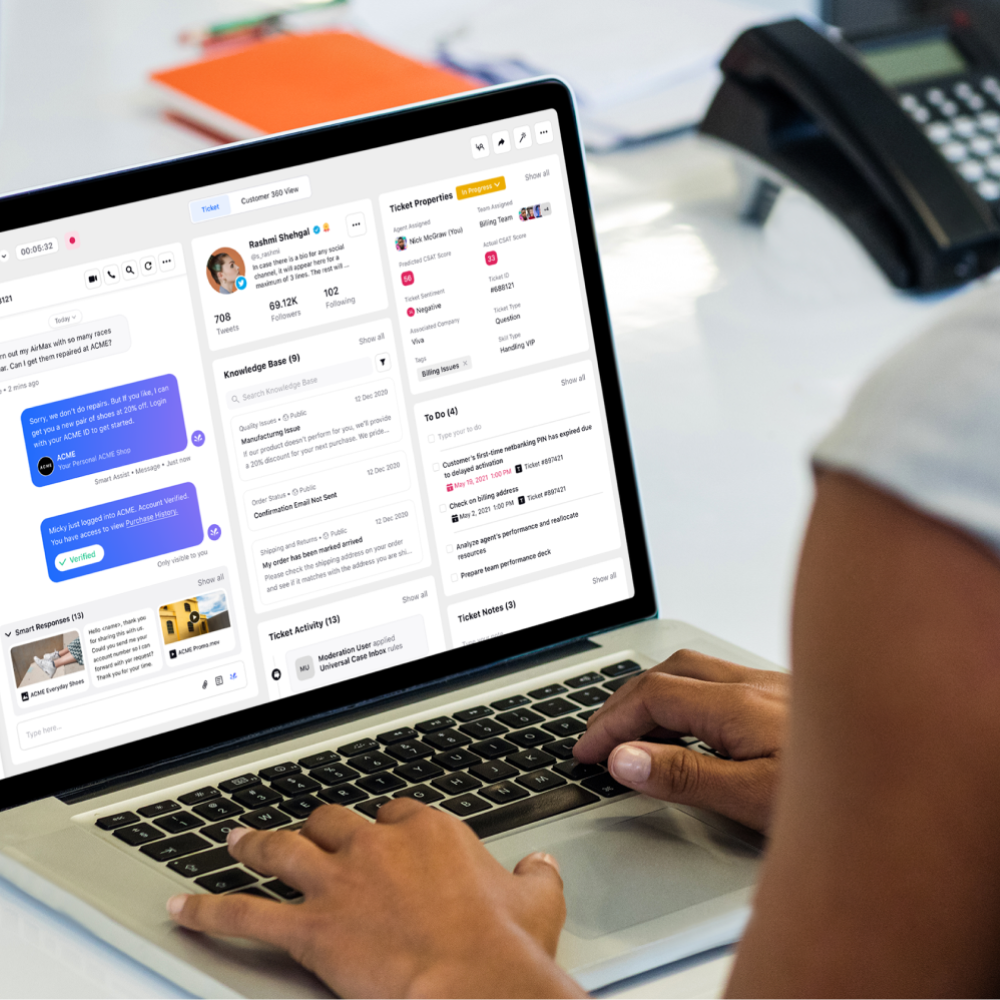
是什麼讓 Sprinklr 的 NLU 引擎成為對話式 AI 的市場領導者?
Sprinklr 的 AI 引擎專門用於理解和情境化整個客戶體驗管理範圍。 以下是 Sprinklr AI 與傳統對話式 AI 平台不同的七個區別:
1.準確的消息分類
自動閱讀、破譯和分析客戶信息,將它們分類為意圖,並定義內部團隊以進行準確的案例分配。
2. 勤奮的危機檢測
當客戶交互失控時,使用預先確定的參數(例如負面品牌提及和關鍵字)或 AI 識別的痛苦跡象(例如情緒檢測)觸發警報。
3. 情境感知虛擬協助
根據可用的客戶數據、知識庫和跨渠道交互歷史,生成對客戶的自動響應或向代理提供 AI 幫助。
4. 面向未來的預測分析
不僅可以預見客戶服務,還可以預見市場趨勢,例如熱門話題、宏觀經濟、消費者情緒、公關危機和不斷變化的行業基準,以重新調整您的產品和營銷路線圖。 Sprinklr 的 AI 可以通過上下文數據細分識別跨數字渠道、客戶人口統計等的模式。

5. 智能視覺解讀
處理品牌和客戶交互中涉及的視覺數據,以在沒有人工代理的情況下準確定義圖像和視頻。
6.端到端AI工作室
在 Sprinklr 中訓練、測試和部署 AI 模型,以實現更好的社交聆聽、消息分類、對話式 AI 和聊天機器人、響應自動化和自助社區。
7.品牌互動節制
監控每一次座席與客戶的互動,以確保遵守內部品牌指南,並生成報告以確定提高客戶滿意度 (CSAT) 和減少主要聯繫驅動因素的改進領域。
您想通過零接觸個性化和運營效率來擴展您的客戶支持嗎? Sprinklr 的 NLU 引擎可以成為您需要的橋樑——它帶有數百萬個 AI 預測、數據點和數百個可立即部署的 AI 模型。
開始免費試用 Modern Care Lite
了解 Sprinklr 如何使用基礎 AI 幫助企業在 13 個以上的渠道上提供優質體驗,以便您可以在整個客戶體驗中傾聽、路由、解決和衡量。