
使用 Word2Vec 進行主題建模
已發表: 2022-05-02一個詞是由它所擁有的公司定義的。 這就是 Word2Vec 背後的前提,這是一種將單詞轉換為數字並在多維空間中表示它們的方法。 在文檔集合(語料庫)中頻繁出現的單詞也將在此空間中出現。 據說它們在上下文中是相關的。
Word2Vec 是一種機器學習方法,需要語料庫和適當的訓練。 兩者的質量都會影響其準確建模主題的能力。 在檢查非常具體和復雜的主題的輸出時,任何缺點都變得很明顯,因為這些是最難精確建模的。 Word2Vec 可以單獨使用,儘管它經常與其他建模技術結合使用以解決其局限性。
本文的其餘部分提供有關 Word2Vec 的其他背景、它的工作原理、它在主題建模中的使用方式以及它所面臨的一些挑戰。
什麼是 Word2Vec?
2013 年 9 月,Google 研究人員 Tomas Mikolov、Kai Chen、Greg Corrado 和 Jeffrey Dean 發表了論文“向量空間中單詞表示的有效估計”(pdf)。 這就是我們現在所說的 Word2Vec。 該論文的目標是“引入可用於從包含數十億單詞和詞彙表中的數百萬單詞的龐大數據集中學習高質量單詞向量的技術。”
在此之前,任何自然語言處理技術都將單詞視為單數單位。 他們沒有考慮單詞之間的任何相似性。 雖然這種方法有正當的理由,但它確實有其局限性。 在某些情況下,縮放這些基本技術無法提供顯著改進。 因此,需要開發先進的技術。
該論文表明,計算要求較低的簡單模型可以訓練高質量的詞向量。 正如論文總結的那樣,“有可能從更大的數據集中計算出非常準確的高維詞向量”。 他們談論的是包含一萬億個單詞的文檔集合(語料庫),提供了幾乎無限大小的詞彙表。
Word2Vec 是一種將單詞轉換為數字的方法,在這種情況下為向量,以便可以在數學上發現相似之處。 這個想法是相似詞的向量在向量空間內分組。
想想地圖上的緯度和經度坐標。 使用這個二維向量,您可以快速確定兩個位置是否相對靠近。 對於要在向量空間中適當表示的單詞,二維是不夠的。 因此,向量需要包含許多維度。
Word2Vec 如何工作?
Word2Vec 將大型文本語料庫作為其輸入,並使用淺層神經網絡對其進行矢量化。 輸出是一個單詞列表(詞彙表),每個單詞都有一個對應的向量。 具有相似含義的單詞在空間上非常接近。 在數學上,這是通過餘弦相似度來衡量的,其中總相似度表示為 0 度角,而沒有相似度表示為 90 度角。
可以使用不同類型的模型將單詞編碼為向量。 在他們的論文中,Mikolov 等人。 研究了兩個現有模型,前饋神經網絡語言模型(NNLM)和遞歸神經網絡語言模型(RNNLM)。 此外,他們提出了兩個新的對數線性模型,連續詞袋(CBOW)和連續 Skip-gram。
在他們的比較中,CBOW 和 Skip-gram 表現更好,所以讓我們來看看這兩個模型。
CBOW 與 NNLM 類似,依賴於上下文來確定目標詞。 它根據它之前和之後的單詞來確定目標單詞。 米科洛夫發現最好的表現出現在四個未來和四個歷史詞上。 之所以稱為“詞袋”,是因為歷史中單詞的順序不會影響輸出。 術語 CBOW 中的“連續”是指其使用“上下文的連續分佈式表示”。
Skip-gram 是 CBOW 的反面。 給定一個單詞,它會預測特定範圍內的周圍單詞。 更大的範圍提供了更好質量的詞向量,但增加了計算複雜度。 較遠的術語被賦予較少的權重,因為它們通常與當前單詞的相關性較小。
在比較 CBOW 和 Skip-gram 時,發現後者在大型數據集上提供了更好的質量結果。 儘管 CBOW 更快,但 Skip-gram 可以更好地處理不常用的單詞。
在訓練期間,為每個單詞分配一個向量。 調整該向量的分量,使相似的詞(基於它們的上下文)更接近。 將其視為一場拔河比賽,每次在空間中添加另一個術語時,單詞都會在這個多維向量中被推拉。
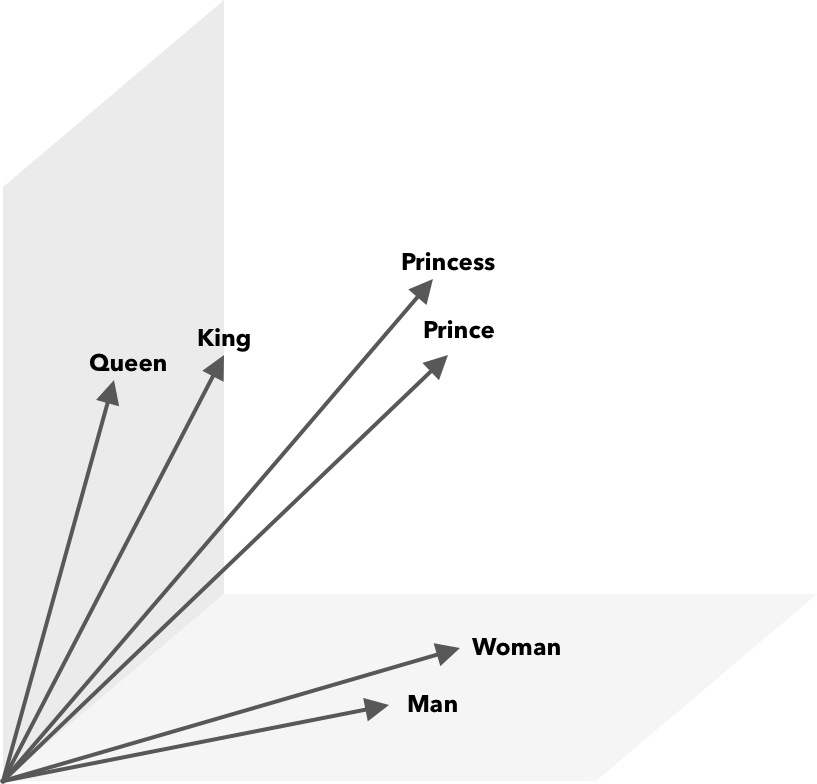
除了余弦相似度之外,還可以對詞向量執行數學運算。 例如,vector(”King”) – vector(”Man”) + vector(”Woman”) 得到的向量最接近表示單詞 Queen 的向量。
用於主題建模的 Word2Vec
可以直接查詢 Word2Vec 創建的詞彙表以檢測單詞之間的關係或輸入深度學習神經網絡。 CBOW 和 Skip-gram 等 Word2Vec 算法的一個問題是它們對每個單詞的權重相等。 處理文檔時出現的問題是單詞不能平等地代表句子的含義。

有些詞比其他詞更重要。 因此,通常採用不同的加權策略,例如 TF-IDF 來處理這種情況。 這也有助於解決下一節中提到的 hubness 問題。 Searchmetrics ContentExperience 使用 TF-IDF 和 Word2Vec 的組合,您可以在此處閱讀我們與 MarketMuse 的比較。
雖然 Word2Vec 等詞嵌入捕獲形態、語義和句法信息,但主題建模旨在發現語料庫中的潛在語義結構或主題。
根據 Budhkar 和 Rudzicz (PDF) 的說法,將潛在 Dirichlet 分配 (LDA) 與 Word2Vec 相結合可以產生區分特徵,以“解決由於這些模型中缺少上下文信息而導致的問題”。 可以在這個 DataCamp 教程中找到更容易閱讀 LDA2vec。
Word2Vec 的挑戰
一般來說,詞嵌入存在幾個問題,包括 Word2Vec。 我們將涉及其中的一些,更詳細的分析,請參閱 Amir Bakarov 的“詞嵌入評估方法調查”(pdf)。 語料庫及其大小以及訓練本身將顯著影響輸出質量。
你如何評價輸出?
正如 Bakarov 在他的論文中解釋的那樣,NLP 工程師通常會以不同於計算語言學家或內容營銷人員的方式評估嵌入的性能。 以下是論文中引用的一些其他問題。
- 語義是一個模糊的概念。 “好的”詞嵌入反映了我們的語義概念。 但是,我們可能不知道我們的理解是否正確。 此外,單詞具有不同類型的關係,例如語義相關性和語義相似性。 詞嵌入應該反映哪種關係?
- 缺乏適當的訓練數據。 在訓練詞嵌入時,研究人員經常通過根據數據調整它們來提高它們的質量。 這就是我們所說的曲線擬合。 研究人員不應使結果適合數據,而應嘗試捕捉單詞之間的關係。
- 內在方法和外在方法之間缺乏相關性意味著不清楚哪種方法是首選。 外部評估決定了在其他自然語言處理任務中進一步下游使用的輸出質量。 內在評價依賴於人類對詞語關係的判斷。
- 中心問題。 Hubs,表示常用詞的詞向量,接近於過多的其他詞向量。 這種噪音可能會使評估產生偏差。
此外,特別是 Word2Vec 存在兩個重大挑戰。
- 它不能很好地處理歧義。 結果,一個多義詞的向量反映的是平均值,這很不理想。
- Word2Vec 無法處理詞彙表外 (OOV) 單詞和形態相似的單詞。 當模型遇到一個新概念時,它會求助於使用隨機向量,這不是一個準確的表示。
概括
使用 Word2Vec 或任何其他詞嵌入並不能保證成功。 質量輸出取決於使用適當且足夠大的語料庫進行適當培訓。
雖然評估輸出質量可能很麻煩,但這裡有一個針對內容營銷人員的簡單解決方案。 下次您評估內容優化器時,請嘗試使用非常具體的主題。 以這種方式進行測試時,質量差的主題模型會失敗。 它們適用於一般條款,但當請求過於具體時就會崩潰。
因此,如果您使用“如何種植鱷梨”這一主題,請確保這些建議與種植植物有關,而不是一般的鱷梨。
MarketMuse NLG 技術自然語言生成幫助創建了這篇文章。
你現在應該做什麼
當您準備就緒時……我們可以通過以下 3 種方式幫助您更快地發布更好的內容:
- 與 MarketMuse 預約時間 與我們的一位策略師安排現場演示,了解 MarketMuse 如何幫助您的團隊實現其內容目標。
- 如果您想了解如何更快地創建更好的內容,請訪問我們的博客。 它充滿了幫助擴展內容的資源。
- 如果您認識其他喜歡閱讀此頁面的營銷人員,請通過電子郵件、LinkedIn、Twitter 或 Facebook 與他們分享。