
什麼是抓取預算以及如何以智能方式對其進行優化?
已發表: 2021-08-19目錄
抓取預算分析是任何 SEO 專家的工作職責之一(特別是如果他們正在處理大型網站)。 一項重要的任務,在谷歌提供的材料中得到了很好的介紹。 然而,正如你在 Twitter 上看到的那樣,即使是谷歌員工也淡化了抓取預算在獲得更好的流量和排名方面的作用:
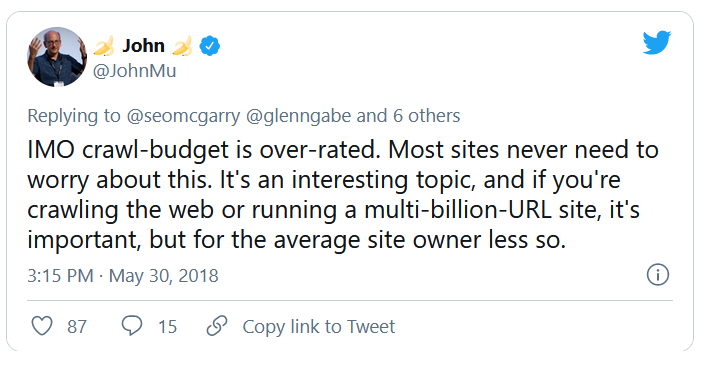

他們對這個正確嗎?
Google 如何工作和收集數據?
當我們提出這個話題時,讓我們回顧一下搜索引擎是如何收集、索引和組織信息的。 在您以後在網站上的工作中,將這三個步驟牢記在心是必不可少的:
第 1 步:爬行。 搜索在線資源,目的是發現和瀏覽所有現有的鏈接、文件和數據。 通常,Google 從網絡上最受歡迎的地方開始,然後繼續掃描其他不太流行的資源。
第 2 步:索引。 Google 會嘗試確定該頁面的內容以及所分析的內容/文檔是否構成獨特或重複的材料。 在這個階段,谷歌對內容進行分組並建立重要性順序(通過閱讀rel=”canonical”或rel=”alternate”標籤中的建議或其他方式)。
第 3 步:上菜。 一旦被分割和索引,數據就會顯示出來以響應用戶查詢。 這也是谷歌通過考慮用戶位置等因素對數據進行適當排序的時候。
重要提示:許多可用材料忽略了第 4 步:內容渲染。 默認情況下,Googlebot 會將文本內容編入索引。 然而,隨著網絡技術的不斷發展,谷歌不得不設計新的解決方案來停止“閱讀”並開始“看到”。 這就是渲染的全部內容。 它服務於谷歌,以顯著提高其在新推出的網站中的影響力並擴大索引。
注意:內容呈現問題可能是爬網預算失敗的原因。
抓取預算是多少?
抓取預算只不過是抓取工具和搜索引擎機器人可以索引您的網站的頻率,以及它們在一次抓取中可以訪問的 URL 總數。 將您的抓取預算想像為您可以在服務或應用程序中花費的積分。 如果您不記得“收取”您的抓取預算,機器人會放慢速度並減少您的訪問次數。
在 SEO 中,“收費”是指為獲取反向鏈接或提高網站的整體知名度所做的工作。 因此,抓取預算是整個 Web 生態系統不可或缺的一部分。 當您在內容和反向鏈接方面做得很好時,您就提高了可用抓取預算的限制。
在其資源中,谷歌沒有冒險明確定義抓取預算。 相反,它指出了影響 Googlebot 的徹底性和訪問頻率的兩個基本抓取組件:
- 抓取速度限制;
- 抓取需求。
什麼是抓取速度限制以及如何檢查?
簡單來說,抓取速度限制是 Googlebot 在抓取您的網站時可以建立的同時連接數。 由於 Google 不想損害用戶體驗,因此它會限制連接數以保持您的網站/服務器的流暢性能。 簡而言之,您的網站越慢,您的抓取速度限制就越小。
重要提示:抓取限制還取決於您網站的整體 SEO 健康狀況——如果您的網站觸發了許多重定向、404/410 錯誤,或者服務器經常返回 500 狀態代碼,那麼連接數也會下降。
您可以使用 Google Search Console 中的Crawl Stats 報告中提供的信息來分析抓取速率限制數據。
爬取需求,或網站受歡迎程度
雖然抓取速度限制要求您完善網站的技術細節,但抓取需求會獎勵您網站的受歡迎程度。 粗略地說,您網站(及其上)的嗡嗡聲越大,其抓取需求就越大。
在這種情況下,谷歌盤點了兩個問題:
- 總體受歡迎程度——谷歌更渴望對互聯網上普遍流行的 URL 進行頻繁的爬網(不一定是那些來自最多 URL 的反向鏈接)。
- 索引數據的新鮮度——Google 力求只提供最新信息。 重要提示:創建越來越多的新內容並不意味著您的總體抓取預算限制會上升。
影響爬取預算的因素
在上一節中,我們將抓取預算定義為抓取速率限制和抓取需求的組合。 請記住,您需要同時處理這兩個問題,以確保正確抓取您的網站(並因此編制索引)。
您將在下面找到在抓取預算優化期間要考慮的簡單要點列表
- 服務器——主要問題是性能。 您的速度越低,Google 分配更少資源來索引您的新內容的風險就越高。
- 服務器響應代碼——您網站上的 301 重定向和 404/410 錯誤的數量越多,您獲得的索引結果就越差。 重要提示:注意重定向循環 - 每個“跳躍”都會降低您網站的爬取率限制,以便機器人下次訪問。
- robots.txt 中的塊——如果您的 robots.txt 指令基於直覺,您最終可能會造成索引瓶頸。 結果:您將清理索引,但以犧牲新頁面的索引效率為代價(當被阻止的 URL 牢固地嵌入整個網站的結構中時)。
- 分面導航/會話標識符/URL 中的任何參數——最重要的是,請注意以下情況:帶有一個參數的地址可能會被進一步參數化,而沒有任何限制。 如果發生這種情況,Google 將訪問無限數量的地址,將所有可用資源用於我們網站的次要部分。
- 重複的內容——複製的內容(除了自相殘殺)會嚴重損害索引新內容的有效性。
- Thin Content – 當頁面的文本與 HTML 的比率非常低時會發生這種情況。 因此,Google 可能會將頁面識別為所謂的 Soft 404 並限制對其內容的索引(即使內容有意義,例如,在製造商的頁面上展示單一產品且沒有唯一文字內容)。
- 內部鏈接不良或缺乏。
抓取預算分析的有用工具
由於抓取預算沒有基準(這意味著很難比較網站之間的限制),因此請配備一組旨在促進數據收集和分析的工具。
谷歌搜索控制台
多年來,GSC 成長得很好。 在抓取預算分析期間,我們應該查看兩個主要報告:索引覆蓋率和抓取統計信息。
GSC 中的指數覆蓋率
該報告是一個海量數據源。 讓我們檢查有關從索引中排除的 URL 的信息。 這是了解您面臨的問題規模的好方法。
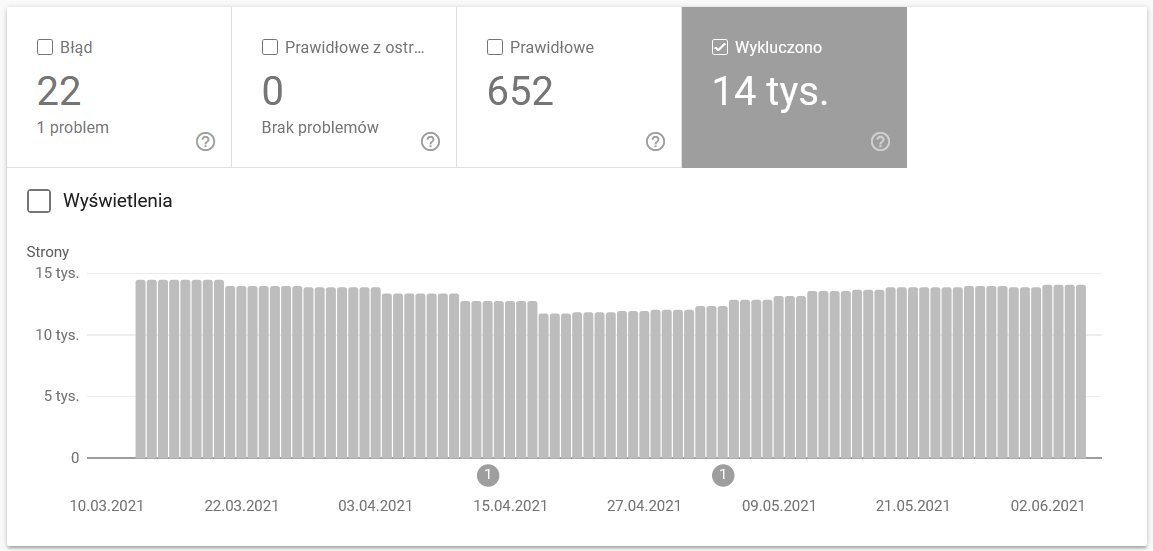
整個報告值得單獨寫一篇文章,所以現在,讓我們關注以下信息:
- 被“noindex”標籤排除——一般來說,更多的 noindex 頁面意味著更少的流量。 這就引出了一個問題——將它們保留在網站上的意義何在? 如何限制對這些頁面的訪問?
- 已抓取 - 當前未編入索引- 如果您看到該內容,請檢查內容在 Googlebot 眼中是否正確呈現。 請記住,每個具有該狀態的 URL 都會浪費您的抓取預算,因為它不會產生自然流量。
- 已發現(目前未編入索引)是值得將其放在優先級列表頂部的更令人擔憂的問題之一。
- 在沒有用戶選擇的規範的情況下重複 - 所有重複頁面都非常危險,因為它們不僅會損害您的抓取預算,還會增加同類相食的風險。
- 重複,谷歌選擇了與用戶不同的規範——理論上,沒有必要擔心。 畢竟,谷歌應該足夠聰明,可以代替我們做出明智的決定。 好吧,實際上,谷歌非常隨機地選擇它的規範——通常會用指向主頁的規範切斷有價值的頁面。
- 軟 404 - 所有“軟”錯誤都非常危險,因為它們可能導致從索引中刪除關鍵頁面。
- 重複的、提交的 URL 未被選為規範- 類似於缺少用戶選擇的規範的狀態報告。
抓取統計
該報告並不完美,就建議而言,我強烈建議也使用良好的舊服務器日誌,這可以更深入地了解數據(以及更多建模選項)。
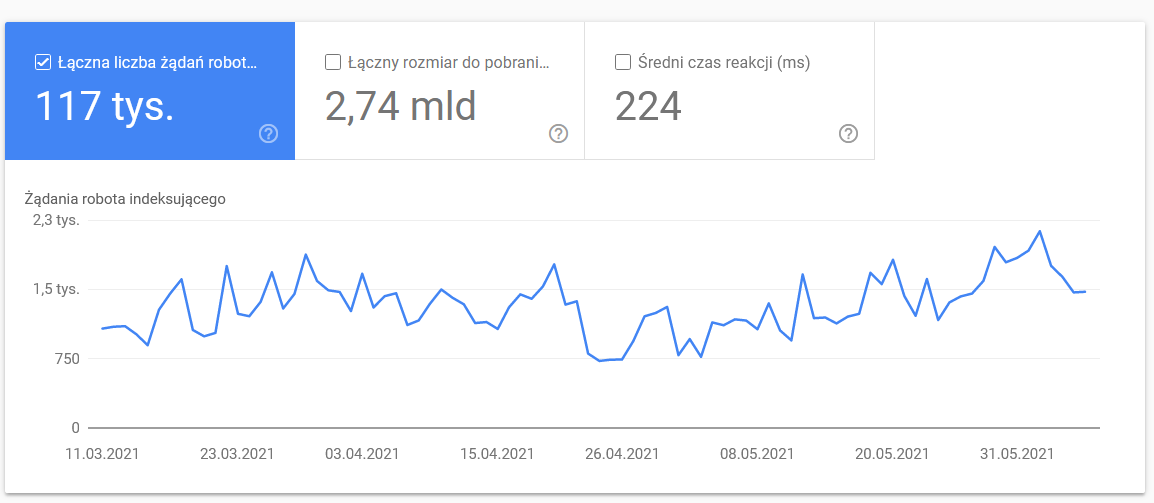
正如我已經說過的,您將很難為上述數字尋找基準。 但是,最好仔細看看:
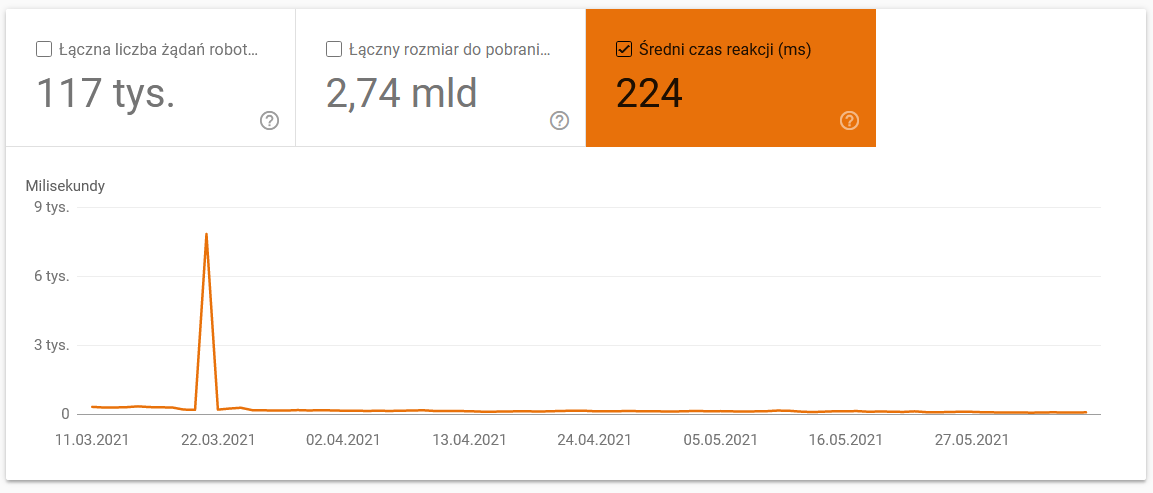
- 平均下載時間。 下面的屏幕截圖顯示,平均響應時間受到了巨大的打擊,這是由於與服務器相關的問題:
- 抓取響應。 總體而言,查看報告以了解您的網站是否存在問題。 密切注意非典型服務器狀態代碼,例如下面的 304。 這些 URL 沒有任何功能用途,但 Google 會浪費資源來抓取其內容。

- 爬行目的。 一般來說,這些數據很大程度上取決於網站上新內容的數量。 谷歌和用戶收集的信息之間的差異可能非常有趣:
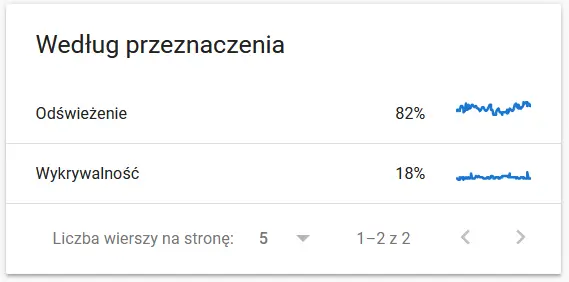
Google 眼中重新抓取的 URL 的內容:
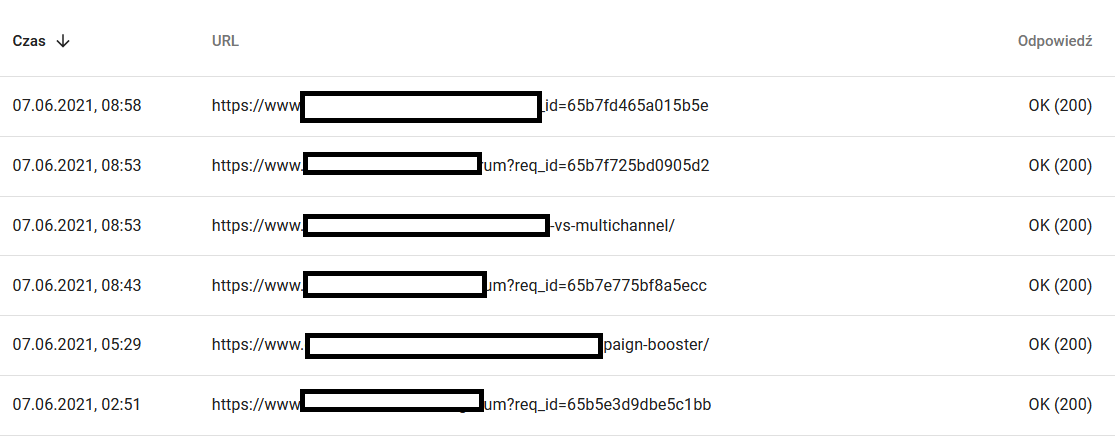
同時,這是用戶在瀏覽器中看到的內容:
絕對是思考和分析的原因:)
- 谷歌機器人類型。 在這裡,您可以讓機器人在銀盤上訪問您的網站,以及它們解析您的內容的動機。 下面的屏幕截圖顯示 22% 的請求涉及頁面資源加載。
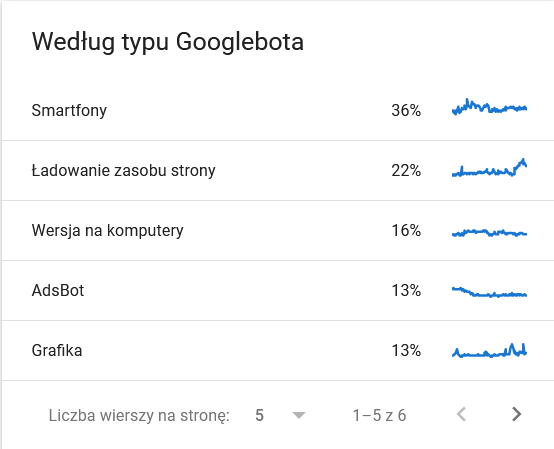
在時間框架的最後幾天,總數激增:
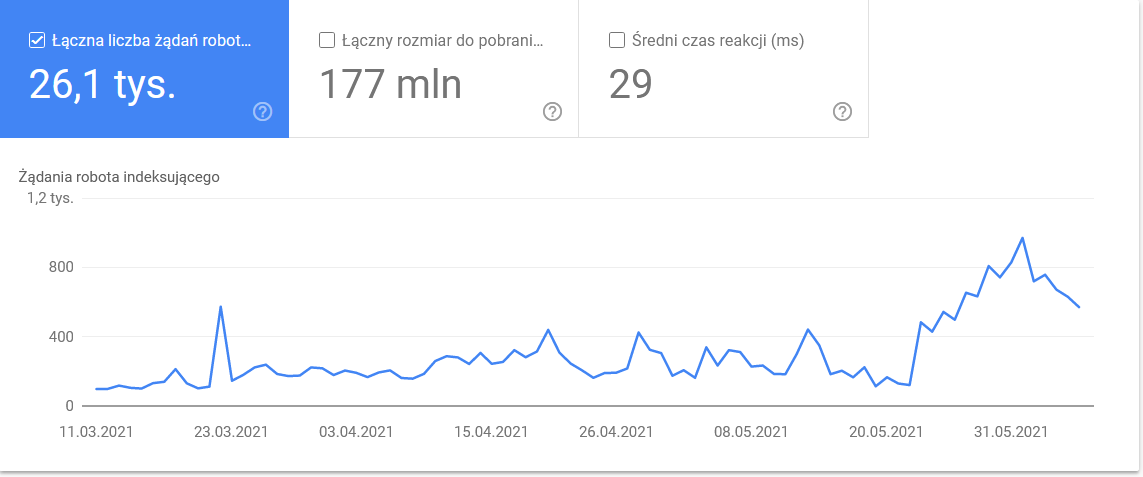
查看詳細信息會發現需要密切注意的 URL:
外部爬蟲(來自 Screaming Frog SEO Spider 的示例)
抓取工具是分析網站抓取預算的最重要工具之一。 他們的主要目的是模仿網站上爬行機器人的動作。 模擬一目了然地向您展示一切是否順利。
如果您是視覺學習者,您應該知道市場上可用的大多數解決方案都提供數據可視化。
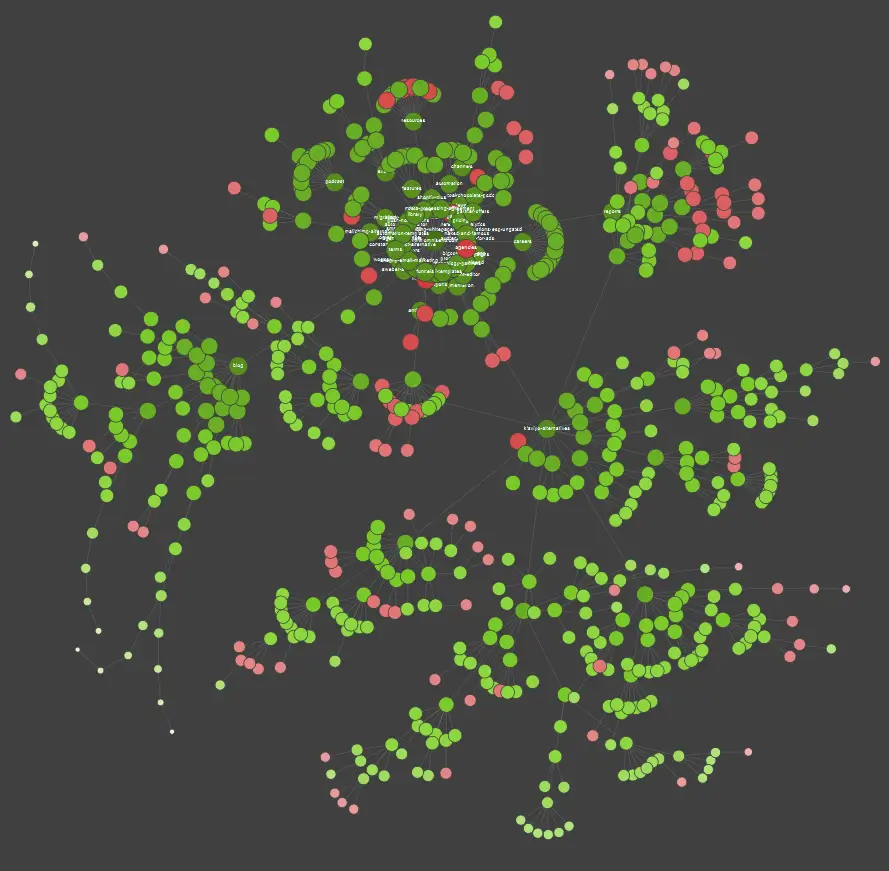
在上面的示例中,紅點代表非索引頁面。 花點時間考慮一下它們的有用性和對網站運營的影響。 如果服務器日誌顯示這些頁面浪費了 Google 的大量時間而沒有增加任何價值 - 是時候認真重新考慮將它們保留在網站上的意義了。

重要提示:如果我們想盡可能準確地重現 Googlebot 的行為,則必須進行正確的設置。 在這裡,您可以從我的計算機中看到示例設置:
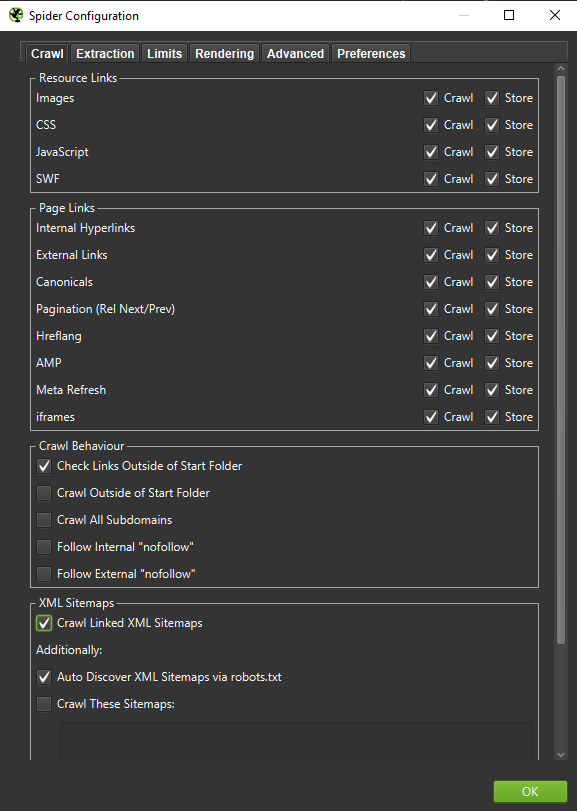
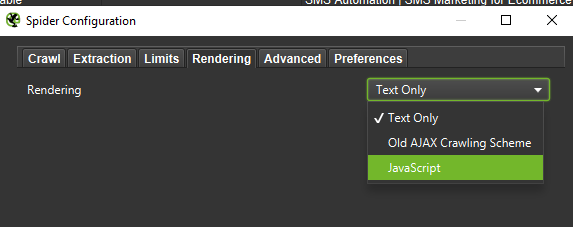
在進行深入分析時,最好測試兩種模式——純文本,還有 JavaScript——來比較差異(如果有的話)。
最後,在兩個不同的用戶代理上測試上面介紹的設置永遠不會有壞處:
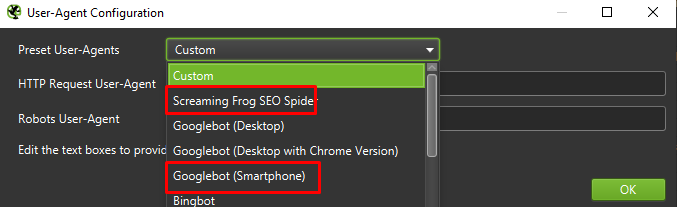
在大多數情況下,您只需關注移動代理抓取/呈現的結果。
重要提示:我還建議利用 Screaming Frog 提供的機會,向您的爬蟲提供來自 GA 和 Google Search Console 的數據。 該集成是一種快速識別抓取預算浪費的方法,例如大量沒有接收流量的潛在冗餘 URL。
日誌分析工具(Screaming Frog Logfile 等)
服務器日誌分析器的選擇是個人喜好問題。 我的首選工具是 Screaming Frog Log File Analyzer。 它可能不是最有效的解決方案(加載大量日誌 = 掛起應用程序),但我喜歡這個界面。 重要的部分是命令系統僅顯示經過驗證的 Googlebot。
可見性跟踪工具
一個有用的幫助,因為它們可以讓您識別您的首頁。 如果一個頁面在 Google 中的許多關鍵字排名很高(= 獲得大量流量),它可能有更大的抓取需求(在日誌中檢查 - Google 真的為這個特定頁面產生更多點擊嗎?)。
出於我們的目的,我們需要 Senuto 中的一般報告——路徑和 URL——以供將來繼續查看。 這兩個報告都在可見性分析的“部分”選項卡中可用。 看一看:
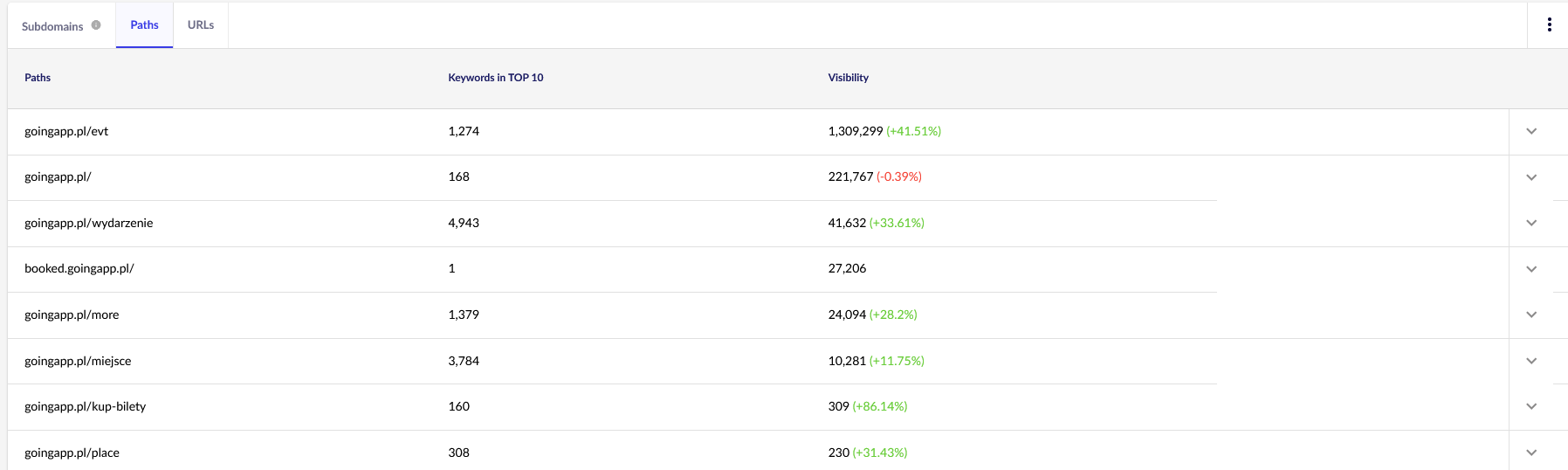
我們的主要興趣點是第二份報告。 讓我們對其進行排序以查看我們的關鍵字可見性(我們的網站在 TOP 10 中排名的關鍵字列表和總數)。 結果將幫助我們確定刺激(和有效分配)我們的抓取預算的主軸。
反向鏈接分析工具(Ahrefs,Majestic)
如果您的某個頁面具有大量入站鏈接,請將其用作您的抓取預算優化策略的支柱。 熱門頁面可以扮演中心的角色,進一步傳遞信息。 此外,具有大量有價值鏈接的流行頁面更有可能吸引頻繁的抓取。
在 Ahrefs 中,我們需要 Pages 報告,確切地說,它的部分標題為:“Best by links”:
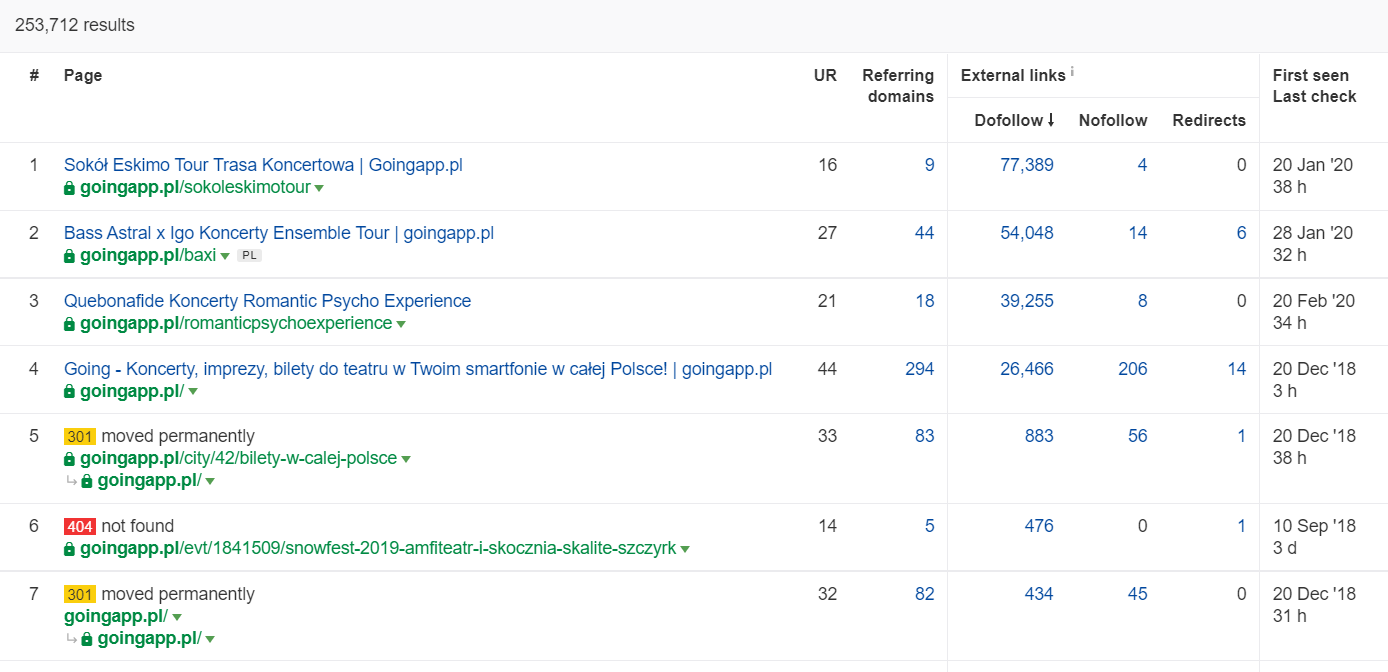
上面的例子表明,一些與音樂會相關的 LP 繼續為反向鏈接生成可靠的統計數據。 即使由於大流行而取消了所有音樂會,使用歷史上強大的頁面來激起爬行機器人的好奇心並將汁液傳播到您網站的更深角落仍然是值得的。
爬行預算問題的明顯跡像是什麼?
意識到您正在處理有問題(過低)的抓取預算並非易事。 為什麼? 主要是因為 SEO 是一個極其複雜的企業。 低排名或索引問題也可能是平庸的鏈接配置文件或網站上缺乏正確內容的結果。
通常,抓取預算診斷涉及檢查:
- 假設您不通過 Google Search Console 請求索引,從發佈到索引新頁面(博客文章/產品)需要多長時間?
- Google 會將無效 URL 保留在其索引中多長時間? 重要提示:重定向地址是一個例外——谷歌會故意存儲它們。
- 您是否有頁面進入索引後才退出?
- Google 在無法產生價值(流量)的頁面上花費了多少時間? 去日誌分析一探究竟。
如何分析和優化爬取預算?
進行爬網預算優化的決定主要取決於您網站的大小。 谷歌建議,一般來說,少於 1000 頁的網站不應該為充分利用其可用的抓取限製而苦惱。 在我的書中,如果您的網站包含 300 多個頁面並且您的內容是動態變化的(例如,您不斷添加新頁面/博客文章),您應該開始爭取更高效和有效的抓取。
為什麼? 這是一個 SEO 衛生問題。 早期實施良好的優化習慣和良好的爬蟲預算管理,以後您將減少整改和重新設計。
抓取預算優化。 標準程序
一般來說,人員預算分析和優化工作包括三個階段:
- 數據收集,這是從網站管理員和外部工具收集我們所知道的關於網站的所有信息的過程。
- 可見性分析和低掛果實的識別。 什麼像發條一樣運轉? 有什麼更好的? 哪些領域的增長潛力最大?
- 爬網預算的建議。
抓取預算審計的數據收集
1. 使用其中一種市售工具執行的完整網站爬網。 目標是至少完成兩次抓取:第一次模擬 Googlebot,而另一個抓取網站作為默認用戶代理(瀏覽器的用戶代理會這樣做)。 在這個階段,您只對下載 100% 的內容感興趣。 如果您注意到爬蟲陷入了循環(當爬了一天之後,我們的硬盤上仍然只有 10% 的網站)——請告知存在問題,您可以停止爬蟲。 對於大型網站,用於分析的合理數量的 URL 大約是 250-30 萬頁。
a) 我們要查找的主要是內部 301 重定向、404 錯誤,以及您的文本可能被歸類為精簡內容的情況。 Screaming Frog 可以選擇檢測近乎重複的內容:
2.服務器日誌。 理想的時間範圍應該是上個月,但是,對於大型網站,最後兩周可能就足夠了。 在最好的情況下,我們應該可以訪問歷史服務器日誌來比較 Googlebot 在一切順利時的動作。
3. 從 Google Search Console 導出數據。 結合上面的第 1 點和第 2 點,Index Coverage 和 Crawl Stats 的數據應該可以讓您對您網站上的所有事件有一個相當全面的描述。
4.有機流量數據。 由 Google Search Console、Google Analytics 以及 Senuto 和 Ahrefs 確定的熱門頁面。 我們希望通過高可見度統計數據、流量或反向鏈接計數來識別所有在人群中脫穎而出的頁面。 這些頁面應該成為您在抓取預算方面工作的支柱。 我們將使用它們來改進對最重要頁面的抓取。
5. 人工索引審核。 在某些情況下,SEO 專家最好的朋友就是一個簡單的解決方案。 在這種情況下:對直接從索引中獲取的數據進行審查! 使用inurl: + site:運算符的組合檢查您的網站是一個很好的選擇。最後,我們需要合併所有收集到的數據。 通常,我們將使用具有允許外部數據導入(GSC 數據、服務器日誌和有機流量數據)功能的外部爬蟲。
可見性分析和低垂的果實
該過程需要單獨的文章,但我們今天的目標是鳥瞰我們的網站目標和所取得的進展。 我們對所有不尋常的事情都感興趣:突然的流量下降(無法用季節性趨勢來解釋)以及有機可見度的同時變化。 我們正在檢查哪些頁面組是最強的,因為它們將成為我們推動 Googlebot 深入我們網站的 HUBS。
在完美的世界中,這樣的檢查應該涵蓋我們網站自推出以來的整個歷史。 但是,隨著數據量每個月都在不斷增長,讓我們專注於分析過去 12 個月期間的可見性和自然流量。
抓取預算——我們的建議
上面列出的活動將根據優化網站的大小而有所不同。 但是,它們是我在執行爬網預算分析時始終考慮的最重要元素。 最重要的目標是消除您網站上的瓶頸。 換句話說,保證 Googlebots(或其他索引代理)的最大可抓取性。
1. 讓我們從基礎開始——消除各種 404/410 錯誤,分析內部重定向並從內部鏈接中刪除它們。 我們應該以最後一次爬行來結束我們的工作。 這一次,所有鏈接都應返回 200 響應代碼,沒有內部重定向或 404 錯誤。
- 在這個階段,最好糾正在反向鏈接報告中檢測到的所有重定向鏈。
2. 抓取後,確保我們的網站結構沒有明顯的重複。
- 還要檢查潛在的蠶食——除了將同一關鍵字定位到多個頁面所產生的問題(簡而言之,您不再控制 Google 將顯示哪個頁面),蠶食會對您的整個抓取預算產生負面影響。
- 將已識別的重複項合併到一個 URL 中(通常是排名較高的 URL)。
3. 檢查有多少個 URL 有 noindex 標籤。 眾所周知,谷歌仍然可以瀏覽這些頁面。 他們只是沒有出現在搜索結果中。 我們正在努力將我們網站結構中的noindex標籤的份額降到最低。
- 舉個例子——博客用標籤組織它的結構; 作者聲稱該解決方案是由用戶方便決定的。 每篇文章都標有 3-5 個標籤,分配不一致且未編入索引。 日誌分析顯示,它是網站上被爬取次數第三多的結構。
4. 查看 robots.txt 。 請記住,實施 robots.txt 並不意味著 Google 不會在索引中顯示地址。
- 檢查哪些被阻止的地址結構仍在被爬取。 也許切斷它們會導致瓶頸?
- 刪除過時/不必要的指令。
5. 分析您網站上非規範 URL 的數量。 Google 不再將rel=”canonical”視為硬性指令。 在許多情況下,搜索引擎完全忽略了該屬性(對索引中的參數進行排序——仍然是一場噩夢)。
6.分析過濾器及其底層機制。 過濾listing是爬蟲預算優化最頭疼的問題。 電子商務企業主堅持實施適用於任何組合的過濾器(例如,按顏色 + 材料 + 尺寸 + 可用性過濾……無數次)。 該解決方案不是最佳的,應限制在最低限度。
7. 網站上的信息架構——一種考慮業務目標、流量潛力和當前鏈接配置文件的架構。 讓我們假設對我們的業務目標至關重要的內容的鏈接應該在站點範圍內(在所有頁面上)或主頁上可見。 當然,我們在這裡進行了簡化,但是主頁和頂部菜單/站點範圍的鏈接是從內部鏈接中建立價值的最有力的指標。 同時,我們正在努力實現最佳的域傳播:我們的目標是我們可以從任何頁面開始抓取並且仍然達到相同數量的頁面(每個 URL 應該有一個最少的傳入鏈接) .
- 努力建立強大的信息架構是爬網預算優化的關鍵要素之一。 它允許我們從一個位置釋放一些機器人資源並將它們重定向到另一個位置。 這也是最大的挑戰之一,因為它需要業務利益相關者的合作——這通常會導致巨大的戰鬥和批評,從而破壞了 SEO 建議。
8.內容渲染。 對於旨在將其內部鏈接基於捕獲用戶行為的推薦系統的網站而言至關重要。 最重要的是,這些工具中的大多數都依賴於 cookie 文件。 Google 不存儲 Cookie,因此不會獲得自定義結果。 結果:谷歌總是看到相同的內容或根本沒有內容。
- 阻止 Googlebot 訪問關鍵的 JS/CSS 內容是一個常見的錯誤。 這一舉措可能會導致頁面索引問題(並浪費 Google 的時間來呈現不可用的內容)。
9. 網站性能 – Core Web Vitals 。 雖然我對 CWV 對網站排名的影響持懷疑態度(出於多種原因,包括商用設備的多樣性和互聯網連接速度的不同),但它是最值得與編碼人員討論的參數之一。
10. Sitemap.xml - 檢查它是否有效並包含所有關鍵元素(只有返回 200 狀態代碼的規範 URL)。
- 我對優化 sitemap.xml 的第一個建議是按類型或(如果可能的話)類別來劃分您的頁面。 該部門將讓您完全控制 Google 的移動和內容索引。